本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
信息熵是机器学习中一个常用的基本概念,它是信息量的延伸概念
信息熵一般用于表示事件的混沌性,在逻辑回归和决策树等模型都涉及到信息熵的相关知识
本文讲解信息熵、香农信息熵等相关概念与计算公式,以及信息熵的意义,快速了解信息熵是什么意思
本节介绍信息熵的定义和信息熵的计算公式
信息熵的定义与计算公式
信息熵是机器学习中常用的概念,信息熵通俗来说就是信息量的期望
设有n种取值,取值为的概率为,则x的信息量期望称为信息熵
信息熵计算公式如下:
特别地,当取为香农信息量时,称为香农信息熵
香农信息熵公式如下:
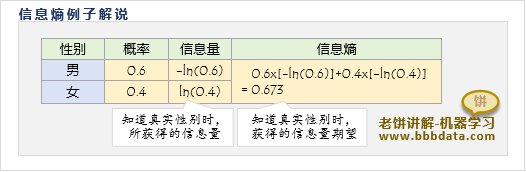
✍️信息熵举例说明
假设已知一个人的性别为男、女的概率分别为
那么对任意一个人,在知道他是男/女的时候,分别获得信息量
因此,在知道性别时获得的信息量期望为,即信息熵
本节介绍信息熵常用的意义与作用
信息熵的用途-变量价值判断
信息熵在机器学习中的应用无处不在,其中一个就是用来判断变量的价值
假设有两个变量,我们只能知道其中一个变量的值,那么,我们应该选择知道哪一个呢?
此时,可以根据变量的信息熵来判断变量的价值,它代表知道变量的值时所获得的信息量期望
因此在评估变量价值时,往往可以用信息熵来对变量的价值进行量化,信息熵越大说明价值越大
信息熵的用途-评估混沌性
信息熵在机器学习中常常用来评估混沌性,例如评估y的混沌性
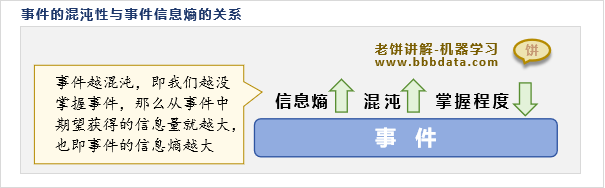
当我们对一个事件越不确定、越混沌时,在得知该事件的确切值时期望获得的信息量就越多
即如果事件对于我们越混沌,我们对事件的掌握越少,事件所包含的信息熵就会越大
因此,机器学习中常用信息熵来评估一个事件的混沌程度,或者我们对事件的掌握程度
1. 对事件的评估
信息熵越小,代表事件越清晰,事件的信息熵越大,代表事件本身越混沌
2. 评估我们对事件的掌握程度
事件的信息熵越大,代表我们对事件的掌握程度越小
事件的信息熵越小,代表我们对事件的掌握程度越大
这里的“事件”在机器学习中一般是指样本的真实y值,因此熵就是我们对y值的掌握程度
机器学习的模型往往就是将X转换为y的信息,去进一步掌握y,了解y,降低我们对于y的混沌性
好了,信息量的概念与意义就写到这了~
End
 评论
评论