本站原创文章,转载请说明来自《老饼讲解-深度学习》www.bbbdata.com
Dropout是深度学习中常用的一种抵抗过拟合的方法,它一般以Dropout层的方式来实现
本文讲解DropOut的原理、具体计算方法,以及DropOut层的结构,并展示具体的代码实现例子
通过本文可以快速了解dropout是什么,为什么要加入dropout,以及如何使用Dropout来增加神经网络的泛化能力
本节讲解什么是Dropout机制,为什么要引入Dropout机制
什么是Dropout机制
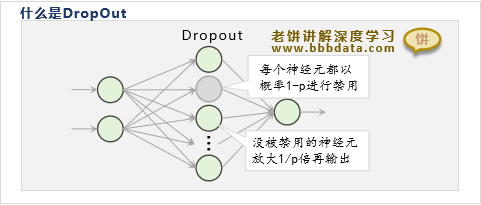
Dropout是深度学习中为了抑制神经网络过拟合而引入的训练机制,示图如下
如果神经网络某层引入Dropout,则会对该层上的神经元以概率1-p进行禁用(即keep概率为p)
同时对该层没被禁用的神经元的输出进行k=1/p倍放大
例如对一个具有10个隐神经元的三层BP神经网络,在隐层引入keep概率p为0.7的Dropout机制
则在训练过程中,每次迭代每个神经元会以0.3的概率禁用,剩余神经元以1/0.7=1.428倍进行输出
Dropout机制的两个特别说明:
1. Dropout只应用于训练阶段
在训练完成后,DropOut则需要移除,即所有神经元都不会被禁用
2. Dropout只应用于神经元非常多的层
Dropout是专门应对隐神经元非常多的层而言的,如果神经元非常少,则不适用Dropout
✍️为什么Dropout剩余的神经元需要以1/p倍进行输出?
Dropout对剩余神经元进行放大输出,主要是为了保持输出值整体期望的稳定性
因为期望上只保留p*100%的神经元,这会导致传输到下一层的值在期望上只有原来的p*100%
因此,先对剩下的p*100%个神经元扩大1/p倍再输出,这样可以保持传到下一层的值在期望上是保持一致的
DropOut的放大系数是基于期望的,应用于神经元非常多的网络上,有微小的偏差无伤大雅,
但如果神经元较少,偏差会有较大的影响,此时最好不要用k=1/p,而改为真实的屏蔽占比
更进一步地来说,神经元较少时,本身就不适合引入Dropout
DropOut为什么能抵抗过拟合
Dropout抵抗过拟合的原理类似于Bagging集成算法
集成学习-bagging集成的思想
在集成学习的bagging集成中,通过训练多个简单的模型,合并在一起,即将多个模型的结果求平均
由于多个模型合并在一起,它们相互借鉴与抵消,所以最终的结果会相对更加平滑,
bagging集成为了降低模型的复杂度,所使用的模型都会较为简单,也即单个模型的预测能力会有所下降
虽然单个模型的预测能力被削弱,但并不影响集成模型的最终效果,这是因为多个模型叠加后,预测能力又得到增强
DropOut的思想
虽然集成学习有很好的抵抗过拟合能力,但对于深层、隐神经元极多的全连接神经网络,就很难使用这样的集成技术,
因为深度学习中单个模型的计算、训练就已经是非常耗时了,集成多个模型并不现实
所以 Dropout的思想是,在训练过程巧妙地、间接地训练多个模型,
对应于集成学习,Dropout相当于该层只有p*N个神经元(相对于N个神经元更加简单)的模型
每次训练时,都只选择了某p*N个神经元来进行训练,而最终模型预测时,则是所有神经元共同预测
当然,Dropout只是思想上借鉴了集成学习,与集成学习并不是完全相同的,
Dropout并没有集成学习那么严谨的理论支持,但Dropout在实践中就是有效的,所以在大型神经网络中广为使用
本节讲述Dropout是如何通过Dropout层来实现的,及Dropout层的计算逻辑
DropOut层是什么
在深度学习中,Dropout机制一般以Dropout层来实现
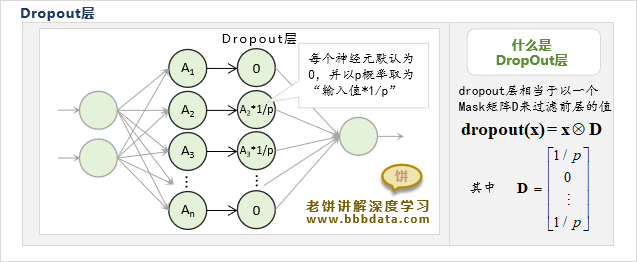
当某层使用Dropout机制时,就在该层之后加入一个Dropout层,如下所示
DropOut层的计算方式如下:
1. Dropout层先生成一个与输入维度一致的向量/矩阵D
其中,D的每个元素默认为0,并以p的概率取值为k=1/p
2. Dropout的输出就是将输入与D进行点乘(哈玛达积)
即
可以看到,引入一个Dropout层实际也就是运用了DropOut机制
深度学习框架中一般都是以DropOut层来实现DropOut机制,这样更加灵活、简洁
DropOut计算例子
下面展示pytorch中Dropout计算例子
import torch
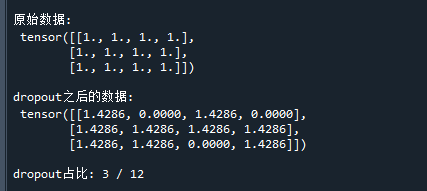
input = torch.ones((3,4)) # 生成一个全为1的矩阵,用于dropout
m = torch.nn.Dropout(p=0.3) # 初始化dropout类,keep的概率为0.3
output = m(input) # 对输入进行dropout
#-------------打印结果-----------------------
print('原始数据:',input)
print('dropout之后的数据:',output)
print('dropout占比:',(output==0).sum().item(),'/',input.numel() )运行结果如下:
可以看到,dropout就是保留keep=0.3的输入,并将进行放大1/0.3=1.4286倍,然后将其它输入置0
本节展示和讲解Dropout在实际应用中的使用方法
DropOut应用示例
在pytorch中可以通过nn.Dropout来插入一个DropOut层
具体代码示例如下:
# DropOut使用示例
from torch import nn
# 定义模型的结构
model = nn.Sequential(
nn.Linear(28*28, 100),
nn.ReLU(inplace=True),
nn.Dropout(p=0.3), # 加入了DropOut层
nn.Linear(100, 10)
)
'''
对模型进行训练,这里省略代码
'''
model.eval() # 训练完后,需要将模型切换到评估状态,这样会屏蔽掉DropOut层如上述代码所示,在训练完模型之后,必须把模型切换到eval状态(评估状态),这样模型才会屏蔽掉Dropout层
因为DropOut只是训练时为了让模型泛化能力更好才引入的机制,评估的时候并不需要Dropout
好了,关于Dropout的机制与Dropout层的运算就讲到这里了~
End
 评论 (本站已停止维护,请前往新站点www.bbblearn.com哦)
评论 (本站已停止维护,请前往新站点www.bbblearn.com哦)