本站原创文章,转载请说明来自《老饼讲解-深度学习》www.bbbdata.com
SGD算法是基于小批样本的训练算法,它是深度学习中最常用、最基础的训练算法
本文讲解SGD算法意义与算法流程,并通过一个具体的代码实例,展示如何用SGD训练MLP神经网络
通过本文可以了解SGD算法是什么,它在深度学习中的意义,以及了解SGD算法是如何训练模型的
本节讲解什么是SGD随机梯度下降算法,以及SGD的算法流程
SGD训练算法
什么是SGD训练算法
SGD的全称为stochastic gradient descent,随机梯度下降
简单来说,SGD就是每次随机抽一个样本来进行梯度下降,无他
而实际中,SGD一般都是抽一批样本(随机小批量梯度下降)来进行梯度下降
SGD在深度学习中最大的意义是:
SGD使得再大的训练集,也可以分批训练,因为SGD为分批训练提供了理论依据
据说,SGD比单纯的梯度下降更快,笔者没有过多去考究文献与原理
SGD的算法流程
SGD的流程如下:
一、初始化待优化参数P
可以使用随机初始化,也可以使用其它的初始化算法
二、训练t步(epoch),每步过程如下:
1. 将数据打乱,并分为n批
2. 逐批训练样本
(1) 计算本批次样本的参数的梯度
(2) 将参数往负梯度方向更新
3. 检验终止条件
终止条件如下:
(1) 如果epoch已经足够大,则终止训练
(2) 如果梯度已经极小,则退出训练
三、输出结果
输出参数P的最终训练结果
本节展示用SGD训练一个MLP的例子,以及具体代码实现
梯度下降法训练MLP-代码示例
如下所示,在sin函数[-5,5]之间采集20个数据,我们需要训练一个三层MLP神经网络,来拟合sin函数x与y的关系
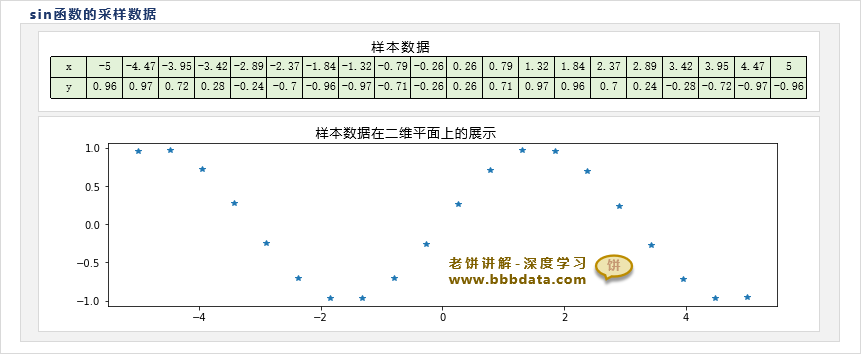
由于样本较为简单,我们不妨将三层MLP神经网络设为4个隐节点,并使用均方差作为损失函数
根据随机批量梯度下降算法SGD的流程,对三层MLP进行训练,
具体代码实现如下:
import torch
import matplotlib.pyplot as plt
import random
torch.manual_seed(99) # 设定torch的随机种子,使每次结果一样
random.seed(99) # 设定python的随机种子,使每次结果一样
# -----计算网络输出:前馈式计算------
def forward(w1,b1,w2,b2,x):
return w2@torch.tanh(w1@x+b1)+b2
# ----计算损失函数: 使用均方差------
def loss(y,py):
return ((y-py)**2).mean()
# -----样本分批函数-----------------
def data_split(x,y,batch_size):
sample_num = x.shape[1] # 样本个数
batch_num = int(sample_num/batch_size) # 计算批数
idx = list(range(sample_num)) # 样本索引
random.shuffle(idx) # 对索引随机打乱
idx = idx[:batch_num*batch_size] # 只抽取batch_num*batch_size个样本
x_batch = x[:,idx] # 打乱x的顺序
y_batch = y[:,idx] # 打乱y的顺序
x_batch = x_batch.view(batch_num,x_batch.shape[0],batch_size) # 转换x的维度
y_batch = y_batch.view(batch_num,y_batch.shape[0],batch_size) # 转换y的维度
return x_batch,y_batch # 返回分批后的数据
# ------训练数据----------------
x = torch.linspace(-5,5,20).reshape(1,20) # 在[-5,5]之间生成20个数作为x
y = torch.sin(x) # 模型的输出值y
#-----------训练模型------------------------
in_num = x.shape[0] # 输入个数
out_num = y.shape[0] # 输出个数
hn = 4 # 隐节点个数
w1 = torch.randn([hn,in_num],requires_grad=True) # 初始化输入层到隐层的权重w1
b1 = torch.randn([hn,1],requires_grad=True) # 初始化隐层的阈值b1
w2 = torch.randn([out_num,hn],requires_grad=True) # 初始化隐层到输出层的权重w2
b2 = torch.randn([out_num,1],requires_grad=True) # 初始化输出层的阈值b2
lr = 0.01 # 学习率
batch_size = 3 # 样本批大小
for epoch in range(5000): # 训练5000步
# 对样本进行分批,逐批训练
x_batch,y_batch = data_split(x,y,batch_size) # 对样本进行分批
for i in range(x_batch.shape[0]): # 逐批次训练
py = forward(w1,b1,w2,b2,x_batch[i]) # 计算网络的输出
L = loss(y_batch[i],py) # 计算损失函数
L.backward() # 用损失函数更新模型参数的梯度
w1.data=w1.data-w1.grad*lr # 更新模型系数w1
b1.data=b1.data-b1.grad*lr # 更新模型系数b1
w2.data=w2.data-w2.grad*lr # 更新模型系数w2
b2.data=b2.data-b2.grad*lr # 更新模型系数b2
w1.grad.zero_() # 清空w1梯度,以便下次backward
b1.grad.zero_() # 清空b1梯度,以便下次backward
w2.grad.zero_() # 清空w2梯度,以便下次backward
b2.grad.zero_() # 清空b2梯度,以便下次backward
# 计算当前的整体损失函数
py = forward(w1,b1,w2,b2,x) # 计算网络的输出
L = loss(y,py) # 计算损失函数
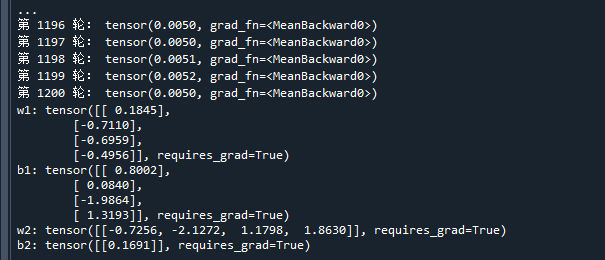
print('第',str(epoch),'轮:',L) # 打印当前损失函数值
if(L.item()<0.005): # 如果误差达到要求
break # 退出训练
px = torch.linspace(-5,5,100).reshape(1,100) # 测试数据,用于绘制网络的拟合曲线
py = forward(w1,b1,w2,b2,px).detach().numpy() # 网络的预测值
plt.scatter(x, y) # 绘制样本
plt.plot(px[0,:],py[0,:]) # 绘制拟合曲线
plt.show() # 展示画布
print('w1:',w1) # 打印w1
print('b1:',b1) # 打印b1
print('w2:',w2) # 打印w2
print('b2:',b2) # 打印b2运行结果如下:
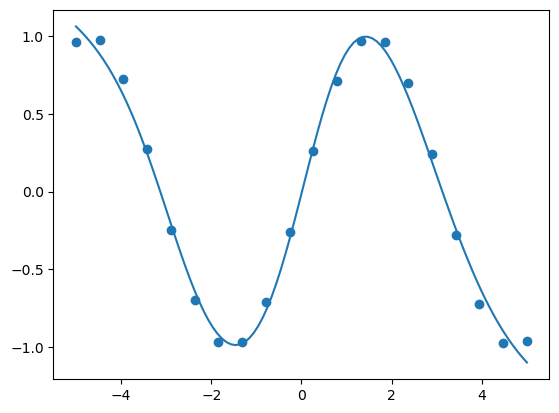
可以看到,模型根据训练数据,已经较好地拟合出sin函数曲线
同时,它的步数相对前面只用梯度下降法时,要相对更少一些
将模型参数代回MLP神经网络的数学表达式,即可得到模型的数学表达式为:
好了,以上就是随机批量梯度下降算法SGD训练MLP神经网络的方法与具体代码例子了~
End
 评论 (本站已停止维护,请前往新站点www.bbblearn.com哦)
评论 (本站已停止维护,请前往新站点www.bbblearn.com哦)