
本站原创文章,转载请说明来自《老饼讲解-深度学习》www.bbbdata.com
"权重衰减"出自AlexNet一文,它是指在训练中不断减小参数的绝对值,是一种常用的正则化方法
本文讲解权重衰减策略的意义与作用,以前展示如何在梯度下降法中加入权重衰减
通过本文,可以了解什么是权重衰减、如何在其它算法中加入权重衰减,如何具体的代码实现
本节介绍深度学习中所说的SGD算法是什么
什么是权重衰减机制
什么是权重衰减
权重衰减(Weight Decay),是指模型训练的过程中,每一步都稍稍缩小模型中参数P的绝对值
即在训练中加入:
其中,是衰减系数,一般设为0.0005
这里的“权重衰减”,应该理解为“待优化参数P的衰减”,
"权重衰减"出自AlexNet一文,由于原文中"待优化参数P"用"权重w"来表示,以致于后来都用"权重衰减"一词来表示
权重衰减的意义
加入权重衰减项的意义主要是衰减待优化参数的绝对值,使得训练出来的参数的绝对值相对会更小一些
一方面是因为参数绝对值过大容易带来过拟合,另一方面权重衰减可以加速神经网络的训练
当参数(权重)绝对值过大时,传给下层的值也更容易趋向极大值,这会导致神经元死亡,从而阻碍训练的速度
总的来说,加入权重衰减,使得神经网络在训练过程中不断减小参数的绝对值,有利于训练和增加网络的泛化能力
如何在训练算法中加入权重衰减
下面参考pytorch里的SGD方法:《torch.optim.SGD》
讲述在梯度下降法、动量梯度下降法中加入权重衰减策略的方法
梯度下降算法-加入权重衰减
在梯度下降算法中,加入权重衰减,只需在每一轮调整完参数后,加入权重衰减即可
具体如下:
梯度下降的迭代公式为:
加入权重衰减后则为 :
也可以写为:
这里的为待训练的参数,为学习率,为梯度, 是衰减系数
动量梯度下降算法-加入权重衰减
在动量梯度下降算法中,加入权重衰减只需修改速度更新公式,如下
动量梯度下降法,速度v的原始更新公式为 :
加入权重衰减后,速度v的更新公式为:
上面的公式,仅参考自pytorch的处理方法,也可紧扣权重衰减的思想,自行设计
本节以梯度下降法为例,展示加入权重衰减后的代码实现
加入权重衰减的梯度下降-代码实现
以求解的最小值为例,它的梯度(即导数)为
下面用加入权重衰减的梯度下降法,求解它的最小值
具体代码实现如下:
"""
本代码用于展示,如果在梯度下降法中加入权重衰减,求解(x-3)**2的最小值
本代码来自《老饼讲解-深度学习》www.bbbdata.com
"""
lr = 0.01 # 设置学习率
lamb = 0.0005 # 设置权重衰减系数
x = 0 # 初始化解
for i in range(1000): # 迭代1000轮
g = 2*(x-3) # 计算梯度
x = x -lr*(g+lamb*x) # 梯度下降的同时,加入权重衰减
print('第',i,'轮,函数值:',(x-3)**2) # 打印当前的函数值
if(abs(g)<0.0001): # 如果梯度过小
break # 退出迭代
print("--结果---") # 打印结果
print('x=',x) # 打印x
print('(x-3)**2=',(x-3)**2) # 打印函数值
代码运行结果如下:
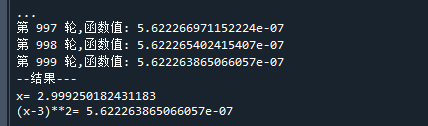
可以看到,它已经非常接近的最小解了
备注:本例不太好体现出权重衰减的特性,仅仅是为了描述在训练算法中加入权重衰减是怎么回事
好了,以上就是训练算法中,权重衰减策略的原理了~
End
 评论 (本站已停止维护,请前往新站点www.bbblearn.com哦)
评论 (本站已停止维护,请前往新站点www.bbblearn.com哦)