本站原创文章,转载请说明来自《老饼讲解-深度学习》www.bbbdata.com
动量梯度下降法是深度学习中训练模型的一种基础算法,它引入了动量的概念,以此优化模型训练效果
本文讲解什么是动量梯度下降法,以及动量梯度下降法如何训练MLP,并展示具体的代码实现例子
通过本文,可以了解动量梯度下降法是什么,如何用动量梯度下降法训练模型,以及具体的代码实现方法
本节介绍动量梯度下降法的思想,以及动量梯度下降法的算法流程
动量梯度下降算法简介
由于梯度下降法使用梯度来进行下降,所以在梯度较小,即较平缓的地方,迭代会较慢
另一方面,梯度下降法只能找到离初始值最近的局部最小值,如果目标函数中有些“小坑”会很吃亏
动量梯度下降法模仿石头滚下山时的场景,在梯度下降法的基础上,引入了动量
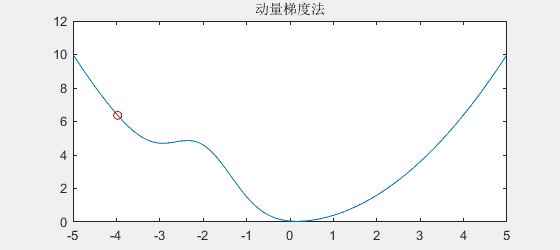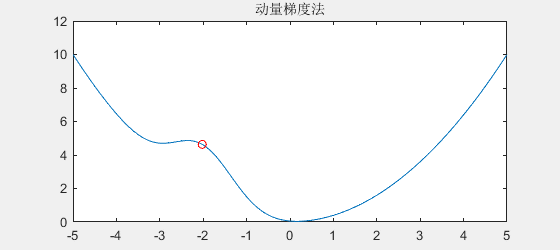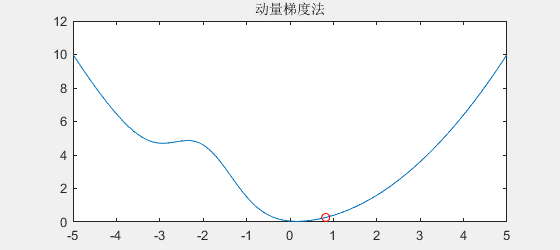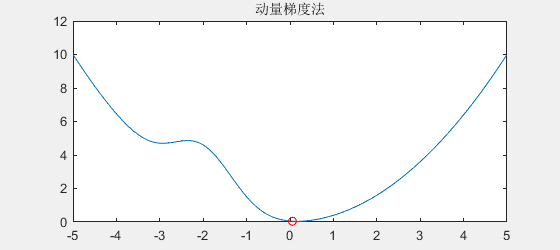
由于石头下滑时拥有动量,所以遇到小坑时能冲出小坑,效果如下:
可以看到,如果函数连续下降,它会越来越快,
即使在平缓地方(例如梯度为0),由于具有动量,它也会维持原来的速度一段时间
另一方面,在遇到"小坑"时,也由于具有动量,所以可以冲出"小坑"
动量梯度下降-算法流程
动量梯度下降算法引入了动量的概念
它使用速度来更新参数,而负梯度则作为加速度,用于更新速度
动量梯度下降算法的具体公式如下
一、 初始化速度与解
初始化速度:
初始化每个待优化参数(即MLP里的所有w,b)
二、迭代
1. 计算当前的速度:
其中,:学习率
:动量系数
:阻尼系数
解说:这里的负梯度就代表加速度
而就是原来速度的权重 ,是当前加速度的权重
然后用加速度更新原来的速度,得到本次的速度
一般与设为同一值,使得与的和为1
2. 使用当前速度来更新参数:
3. 判断是否满足退出条件,如果满足,则退出迭代
本节展示一个用动量梯度下降法训练MLP的代码实现例子
MLP解决数值预测例子-数据说明
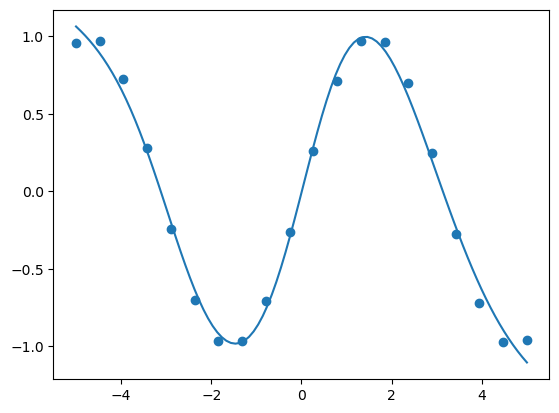
如下所示,在sin函数[-5,5]之间采集20个数据,我们需要训练一个三层MLP神经网络,来拟合sin函数x与y的关系
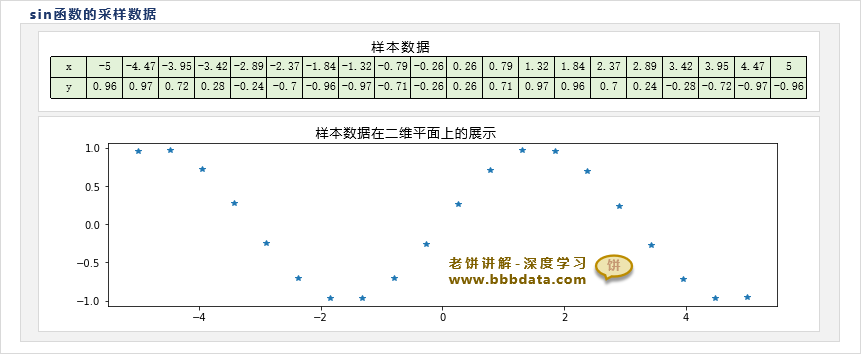
由于样本较为简单,我们不妨将三层MLP神经网络设为4个隐节点,并使用均方差作为损失函数
根据动量梯度下降算法的流程,对三层MLP进行训练,具体代码实现如下:
import torch
import matplotlib.pyplot as plt
torch.manual_seed(99)
# -----计算网络输出:前馈式计算------
def forward(w1,b1,w2,b2,x):
return w2@torch.tanh(w1@x+b1)+b2
# -----计算损失函数: 使用均方差------
def loss(y,py):
return ((y-py)**2).mean()
# -----训练数据----------------------
x = torch.linspace(-5,5,20).reshape(1,20) # 在[-5,5]之间生成20个数作为x
y = torch.sin(x) # 模型的输出值y
#-----------训练模型-----------------
in_num = x.shape[0] # 输入个数
out_num = y.shape[0] # 输出个数
hn = 4 # 隐节点个数
w1 = torch.randn([hn,in_num],requires_grad=True) # 初始化输入层到隐层的权重w1
b1 = torch.randn([hn,1],requires_grad=True) # 初始化隐层的阈值b1
w2 = torch.randn([out_num,hn],requires_grad=True) # 初始化隐层到输出层的权重w2
b2 = torch.randn([out_num,1],requires_grad=True) # 初始化输出层的阈值b2
w1_v = 0 # 初始化w1的速度
b1_v = 0 # 初始化b1的速度
w2_v = 0 # 初始化w2的速度
b2_v = 0 # 初始化b2的速度
lr = 0.01 # 学习率
mu = 0.9 # 动量系数
for i in range(10000): # 训练10000步
py = forward(w1,b1,w2,b2,x) # 计算网络的输出
L = loss(y,py) # 计算损失函数
print('第',str(i),'轮:',L) # 打印当前损失函数值
L.backward() # 用损失函数更新模型参数的梯度
w1_v = mu*w1_v -lr*(1-mu)*w1.grad # 更新w1的速度
b1_v = mu*b1_v -lr*(1-mu)*b1.grad # 更新b1的速度
w2_v = mu*w2_v -lr*(1-mu)*w2.grad # 更新w2的速度
b2_v = mu*b2_v -lr*(1-mu)*b2.grad # 更新b2的速度
w1.data=w1.data+w1_v # 更新模型系数w1
b1.data=b1.data+b1_v # 更新模型系数b1
w2.data=w2.data+w2_v # 更新模型系数w2
b2.data=b2.data+b2_v # 更新模型系数b2
w1.grad.zero_() # 清空w1梯度,以便下次backward
b1.grad.zero_() # 清空b1梯度,以便下次backward
w2.grad.zero_() # 清空w2梯度,以便下次backward
b2.grad.zero_() # 清空b2梯度,以便下次backward
if(L.item()<0.005): # 如果误差达到要求
break # 退出训练
px = torch.linspace(-5,5,100).reshape(1,100) # 测试数据,用于绘制网络的拟合曲线
py = forward(w1,b1,w2,b2,px).detach().numpy() # 网络的预测值
plt.scatter(x, y) # 绘制样本
plt.plot(px[0,:],py[0,:]) # 绘制拟合曲线
plt.show() # 展示画布
print('w1:',w1) # 打印w1
print('b1:',b1) # 打印b1
print('w2:',w2) # 打印w2
print('b2:',b2) # 打印b2运行结果如下:
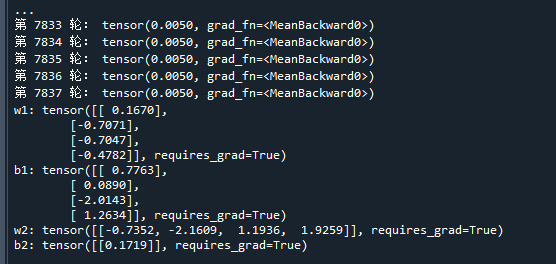
可以看到,模型训练后,已经较好地拟合出sin函数曲线
将模型参数代回MLP神经网络的数学表达式,即可得到模型的数学表达式为:
好了,以上就是使用动量梯度下降法训练MLP的原理与代码例子了~
End
 评论 (本站已停止维护,请前往新站点www.bbblearn.com哦)
评论 (本站已停止维护,请前往新站点www.bbblearn.com哦)