本站原创文章,转载请说明来自《老饼讲解-深度学习》www.bbbdata.com
VGGNet是2014年ILSVRC定位任务第一名、分类任务第二名的CNN模型,它开启了3×3小卷积的应用之路
本文讲解VGGNet的模型结构,以及对其中的VGG16、VGG19模型配置进行详细讲解,并展示VGG模型的具体代码实现
通过本文,可以快速了解VGG卷积神经网络是什么,以及如何使用VGG神经网络来对图像进行类别识别
本节介绍VGG卷积神经网络的模型特色以及模型结构,快速了解VGG是什么
VGGNet卷积神经网络简介
VGGNet是Visual Geometry Group和Google DeepMind公司在2014年共同研发的卷积神经网络
VGGNet在ImageNet大型视觉识别挑战ILSVRC2014中定位任务获得第一名和分类任务第二名
VGGNet原文为《Very Deep Convolutional Networks for Large-Scale Image Recognition》
VGGNet是什么
VGGNet是基于AlexNet的来试验3x3卷积在CNN中的效果而诞生的一系列CNN模型
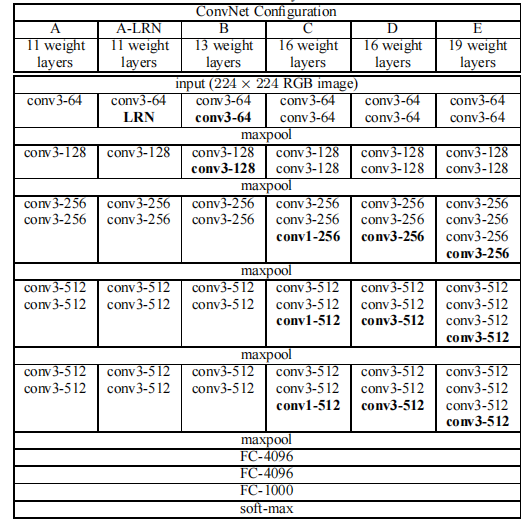
在VGGNet的整个实验过程,一共做了六组模型(A、A-LRN、B、C、D、E模型)
最终的D模型(16层)和E模型(19层)效果最好(两个模型后来又被称为VGG16和VGG19)
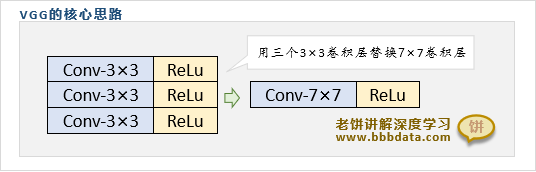
在VGGNet之前比较喜欢用7×7之类的卷积,但VGGNet提出了用多个小卷积来替代大卷积效果会更好
在VGGNet之后,基本就很少见5×5、7×7这些卷积层了,取而代之的是连续使用多个3×3卷积层
VGGNet模型的六组模型分别如下:
VGG主要用于图片类别识别
VGG的输入是:3×224×224的图片
VGG的输出是:1000×1的向量P,Pi代表样本属于第i类的概率
VGG共包括6个模型,各个模型的配置如下:
conv3-128:指的是128个3×3×k的填充1、步幅1的卷积核(k与输入通道数保持一致)
maxpool :指的是使用窗口Size为2×2、步幅为2的Max池化方法
整个实验是对AlexNet的改进,所以整体结构和输入、输出都与AlexNet保持一致
6组模型都保持AlexNet的5大池化层,3个全连接层的结构,只是将卷积层中的大核换成几个小的卷积核层
VGGNet六组模型的设计思路如下:
1. A模型:A模型是整个实验中的Base模型
它只是将AlexNet中的卷积层用几层小核卷积层进行替换(总层数为11)
1、2卷积层换成一个3×3的小核卷积层,3、4、5层换成两个3×3的小核卷积层
2. A-LRN模型:在A的C2层加入LRN(局部归一化)得到模型B,发现没什么用(总层数为11)
3. B模型:抛弃LRN,直接在A上加深C1,C2层,(总层数为13)
4. C模型:在C模型基础上,在C3、C4、C5上各增加一个核Size为1的卷积层(总层数为16)
5. D模型:在C模型基础上,在C3、C4、C5上各增加一个核Size为3的卷积层(总层数为16)
6. E模型:在C模型基础上,在C3、C4、C5上各增加两个核Size为3的卷积层(总层数为19)
最后发现,D(VGG-16)和E(VGG-19)的效果不错,但如果再加深效果就不好了
总的来说,VGGNet就是由VGG团队在AlexNet的基础上进行的一系列对CNN加深实验中得到的一系列模型
整个实验过程共有6个模型,其中D模型VGG-16(16层)和E模型VGG-19(19层)是6个模型中最有价值的两个模型
本节详细讲解VGG-16模型结构和VGG-16的具体运算流程
VGG-16/19模型结构描述
VGG-16模型结构详述
VGG的卷积、池化配置是统一的,如下
卷积配置:3×3的卷积核,填充1,步幅1
池化配置:2×2的池化窗口,步幅2,池化方式:max
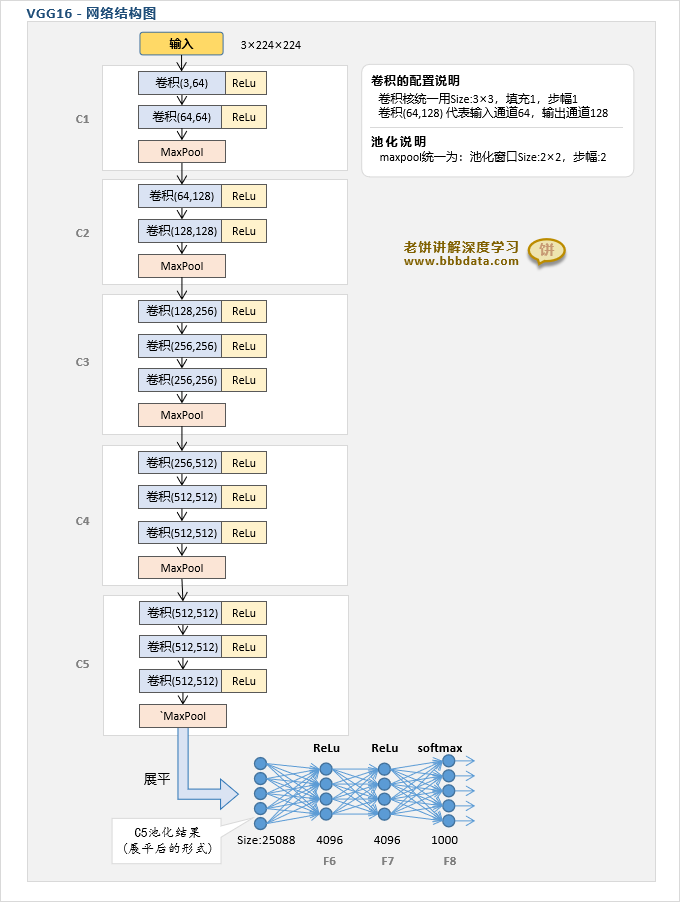
VGG-16各层明细如下:
输入:224×244×3的图像
说明:以下“卷积(a,b)”中的a,b代表卷积的输入和输出通道
C1:卷积(3,64)->ReLu->卷积(64,64)->ReLu->池化
输出Size:112×112×64
C2:卷积(64,128)->ReLu->卷积(128,128)->ReLu->池化
输出Size:56×56×128
C3:卷积(128,256)->ReLu->卷积(256,256)->ReLu->卷积(256,256)->ReLu->池化
输出Size:28×28×256
C4:卷积(256,512)->ReLu->卷积(512,512)->ReLu->卷积(512,512)->ReLu->池化
输出Size:14×14×512
C5:卷积(512,512)->ReLu->卷积(512,512)->ReLu->卷积(512,512)->ReLu->池化
输出Size:7×7×512
F6:全连接层,神经元个数4096,激活函数ReLu(使用p=0.5的Dropout)
F7:全连接层,神经元个数4096,激活函数ReLu(使用p=0.5的Dropout)
F8:全连接层,神经元个数1000(即类别的个数)
VGG-16的输出:将F8的输出进行soft-max就是最终的输出
为方便直观了解VGG-16的模型的整体结构以及运算流程,
笔者绘制了VGG-16的模型结构图如下
VGG-19模型结构详述
VGG-19的结构只是在VGG-16的C3、C4、C5层各加一个卷积层,其它一切与VGG-16一致
VGG-19的C3、C4、C5配置具体如下:
C3:卷积(128,256)->ReLu->卷积(256,256)->ReLu->卷积(256,256)->ReLu->卷积(256,256)->ReLu->池化
输出Size:28×28×256
C4:卷积(256,512)->ReLu->卷积(512,512)->ReLu->卷积(512,512)->ReLu->卷积(512,512)->ReLu->池化
输出Size:14×14×512
C5:卷积(512,512)->ReLu->卷积(512,512)->ReLu->卷积(512,512)->ReLu->卷积(512,512)->ReLu->池化
输出Size:7×7×512
简单来说,VGG-19就是在VGG-16的C3,C4,C5各加一层,共加三层,就变成了VGG-19
为避免内容过于重复,这里不再展示VGG-19的完整结构图,参考VGG-16即可
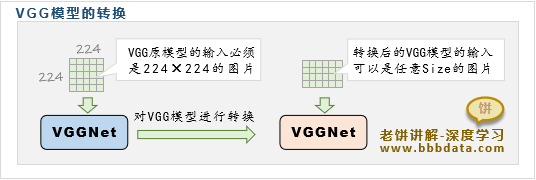
什么是VGG模型转换
VGG论文中提供了模型转换方法,以兼容不同的输入
VGG的原始模型,只支持输入Size为224×224的(或者其它固定尺寸)的图片
为了让VGG模型在应用时去掉这一限制,原文中对训练好的VGG模型进行转换,使它适用于任何尺寸的输入
VGG原模型不支持其它Size的主要原因在于,C5的输出Size会随着输入层Size的改变而改变
当C5的输出Size改变时,就会与第6大层(全连接层)的Size不匹配,导致无法继续前馈运算
VGG将模型转换为适用于任何输入Size的方法主要是将全连接层转为卷积层
利用卷积运算可以兼容不同Size的特性,从而保障VGG模型每层都能够前馈而不出错
具体步骤如下:
1. 将第一个全连接层F6转为7×7的卷积层
2. 将最后两个全连接层F7、F8转为1×1的卷积层
最终F6、F7、F8转换为C6、C7、C8,其结构如下:
C6:卷积->ReLu
卷积核:4096个512×7×7
C7:卷积(4096个4096*1*1)->ReLu
卷积核:4096个4096×1×1
C8:卷积
卷积核:1000(类别个数)个4096×1×1
最后将C8的输出池化为1000×1的size 再进行soft-max就得到最终属于每类别的概率
本节展示如何使用代码实现VGG卷积神经网络
pytorch中的VGG模型
进一步地,可以将pytorch中的VGG模型结构打印出来
具体如下:
import torchvision
model = torchvision.models.vgg16() # 初始化VGG模型
print('\n VGG的模块:\n',dict(model.named_children()) ) # 打印VGG的模块运行结果如下:
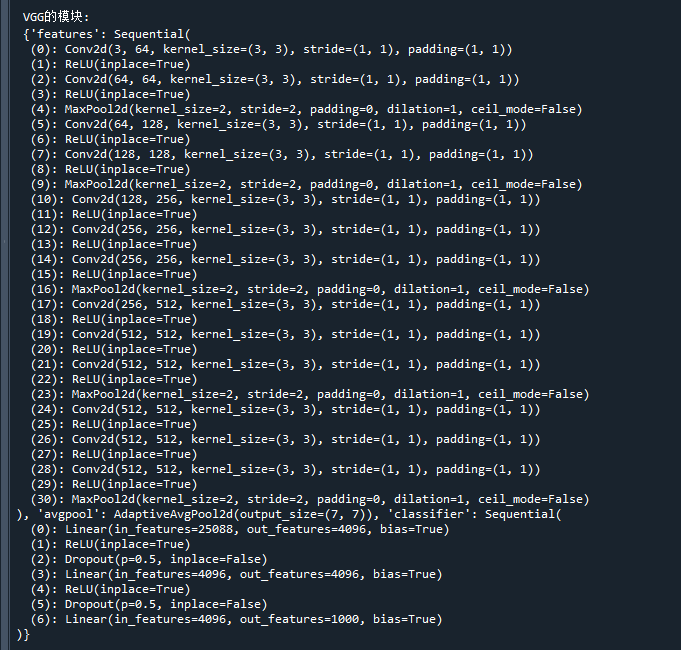
可看到pytorch中VGG16的模型结构基本与原文基本是一致的
VGGNet代码实现
下面展示如何训练一个VGG16卷积神经网络用于图片类别识别
具体代码如下:
import torchvision
from torch import nn
import torch
from torch.utils.data import DataLoader
import numpy as np
model = torchvision.models.vgg16() # 初始化VGG模型,并使用VGG16默认的预训练参数
model.features[0] = nn.Conv2d(1,64, kernel_size=3,stride=1,padding=1) # 修改模型的输入层
model.classifier[6] = nn.Linear(4096,10) # 修改模型的输出层
# print('\n VGG的模块:\n',dict(model.named_children()) )
# 训练函数
def train(dataloader,valLoader,model,epochs,goal,device):
for epoch in range(epochs):
err_num = 0 # 本次epoch评估错误的样本
eval_num = 0 # 本次epoch已评估的样本
print('-----------当前epoch:',str(epoch),'----------------')
for batch, (imgs, labels) in enumerate(dataloader):
# -----训练模型-----
x, y = imgs.to(device), labels.to(device) # 将数据发送到设备
optimizer.zero_grad() # 将优化器里的参数梯度清空
py = model(x) # 计算模型的预测值
loss = lossFun(py, y) # 计算损失函数值
loss.backward() # 更新参数的梯度
optimizer.step() # 更新参数
# ----计算错误率----
idx = torch.argmax(py,axis=1) # 模型的预测类别
eval_num = eval_num + len(idx) # 更新本次epoch已评估的样本
err_num = err_num +sum(y != idx) # 更新本次epoch评估错误的样本
if(batch%10==0): # 每10批打印一次结果
print('err_rate:',err_num/eval_num) # 打印错误率
# -----------验证数据误差---------------------------
model.eval() # 将模型调整为评估状态
val_acc_rate = calAcc(model,valLoader,device) # 计算验证数据集的准确率
model.train() # 将模型调整回训练状态
print("验证数据的准确率:",val_acc_rate) # 打印准确率
if((err_num/eval_num)<=goal): # 检查退出条件
break
print('训练步数',str(epoch),',最终训练误差',str(err_num/eval_num))
# 计算数据集的准确率
def calAcc(model,dataLoader,device):
py = np.empty(0) # 初始化预测结果
y = np.empty(0) # 初始化真实结果
for batch, (imgs, labels) in enumerate(dataLoader): # 逐批预测
cur_py = model(imgs.to(device)) # 计算网络的输出
cur_py = torch.argmax(cur_py,axis=1) # 将最大者作为预测结果
py = np.hstack((py,cur_py.detach().cpu().numpy())) # 记录本批预测的y
y = np.hstack((y,labels)) # 记录本批真实的y
acc_rate = sum(y==py)/len(y) # 计算测试样本的准确率
return acc_rate
# -------模型参数初始化----------------------
def init_param(model):
param_dict = dict(model.named_parameters()) # 获取模型的参数字典
for key in param_dict: # 历遍每个参数,对其初始化
param_name = key.split(".")[-1] # 获取参数的尾缀作为名称
if (param_name=='weight'): # 如果是权重
torch.nn.init.normal_(param_dict[key]) # 则正态分布初始化
elif (param_name=='bias'): # 如果是阈值
torch.nn.init.zeros_(param_dict[key]) # 则初始化为0
#--------------------------主流程脚本----------------------------------------------
#-------------------加载数据--------------------------------
trainsform =torchvision.transforms.Compose([
torchvision.transforms.Resize([224, 224]),
torchvision.transforms.ToTensor(),
]
)
train_data = torchvision.datasets.MNIST(
root = 'D:\pytorch\data' # 路径,如果路径有,就直接从路径中加载,如果没有,就联网获取
,train = True # 获取训练数据
,transform = trainsform # 转换数据
,download = True # 是否下载,选为True,就下载到root下面
,target_transform= None)
val_data = torchvision.datasets.MNIST(
root = 'D:\pytorch\data' # 路径,如果路径有,就直接从路径中加载,如果没有,就联网获取
,train = False # 获取测试数据
,transform = trainsform # 转换数据
,download = True # 是否下载,选为True,就下载到root下面
,target_transform= None)
#-------------------模型训练--------------------------------
trainLoader = DataLoader(train_data, batch_size=30, shuffle=True) # 将数据装载到DataLoader
valLoader = DataLoader(val_data , batch_size=30) # 将验证数据装载到DataLoader
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设置训练设备
init_param(model) # 初始化模型参数
model = model.to(device) # 发送到设备
lossFun = torch.nn.CrossEntropyLoss() # 定义损失函数为交叉熵损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=0.01,momentum =0.9) # 初始化优化器
train(trainLoader,valLoader,model,1000,0.01,device) # 训练模型,训练100步,错误低于1%时停止训练
# -----------模型效果评估---------------------------
model.eval() # 将模型切换到评估状态(屏蔽Dropout)
train_acc_rate = calAcc(model,trainLoader,device) # 计算训练数据集的准确率
print("训练数据的准确率:",train_acc_rate) # 打印准确率
val_acc_rate = calAcc(model,valLoader,device) # 计算验证数据集的准确率
print("验证数据的准确率:",val_acc_rate) # 打印准确率备注:代码未亲测,仅供参考
好了,以上就是VGG卷积神经网络的模型结构与代码实现了~
End
 评论 (本站已停止维护,请前往新站点www.bbblearn.com哦)
评论 (本站已停止维护,请前往新站点www.bbblearn.com哦)