本站原创文章,转载请说明来自《老饼讲解-深度学习》www.bbbdata.com
梯度消失和梯度爆炸是深层神经网络经常出现的一种现象,它阻碍了模型的训练
本文讲解深层神经网络中的梯度爆炸与梯度消失,以及它们带来的危害和预防的基本措施
通过本文,可以了解梯度爆炸与梯度消失是如何产生的,以及如何预防梯度爆炸与梯度消失
本节讲解什么是深度学习中的梯度消失与梯度爆炸
梯度消失与梯度爆炸
梯度消失是指,模型参数的梯度极小,以致于像"消失了"一样
梯度爆炸则是,模型参数的梯度极大,以致于像"爆炸了"一样
当前馈神经网络(例如MLP)的层数很多的时候,就很容易产生梯度消失或梯度爆炸
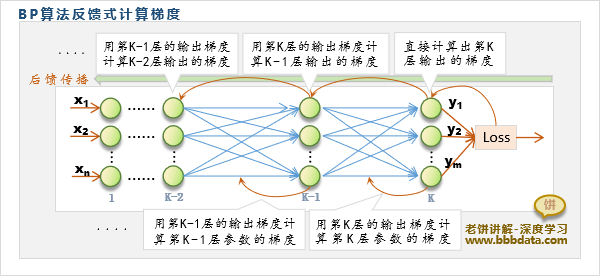
如《BP反向传播算法》所述,前馈神经网络的梯度是层层后馈的,如下:
如图,第k层的输出梯度由第k+1层的输出梯度传播而得,它的梯度为 :
将第k+1层的输出梯度继续展开,则可得到:
在层数很深的时候,即K与k相差较大时,上式的多项连乘就容易会趋于0或趋于极大
此时第k层的输出梯度就会消失或爆炸
而第k层的参数梯度由第k层的输出梯度传播而得,即:
因此,第k层的参数梯度也就会消失或爆炸
总的来说,随着前馈神经网络层数的加深,梯度消失或梯度爆炸就越容易发生
本节讲解梯度消失和梯度爆炸的危害,以及基本预防措施
梯度消失与梯度爆炸的危害
梯度消失或梯度爆炸最大的危害是,它们会为模型的训练带来不可忽略的困难,如下:
当发生梯度消失时,模型参数的梯度趋于0时,参数的更新会极小,也可认为无更新
当梯度爆炸时,模型参数的梯度趋于极大,参数的更新会极大,也可通俗地认为"在乱更新"
因此,梯度消失会令模型训练缓慢,而梯度爆炸则令模型训练不稳定,这都会给模型的训练带来困难
预防梯度消失/爆炸的基本措施
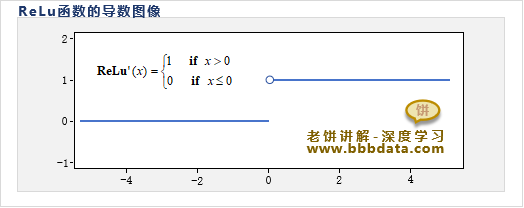
对于MLP等前馈神经网络,缓解梯度消失/爆炸的基本措施就是用ReLu函数替代tanh函数作为激活函数
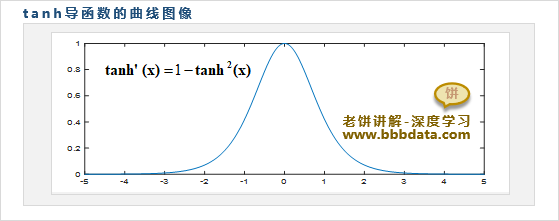
这是因为使用tanh这类型的S型函数作为激活函数,极易引发梯度消失/爆炸,如下:
S型函数的梯度小于1,它在激活区间梯度迅速变化,而在非激活区间梯度几乎为0
由于前馈神经网络的梯度是层层后馈而得到,梯度公式是链式累乘形式
如果前馈神经网络每层都用S型函数作为激活函数,经过层层后馈传播,梯度就极易消失
因此深度学习中一般使用ReLu作为激活函数,它的梯度更加稳定,是缓解梯度消失/爆炸的基本措施
在深度学习中缓解梯度消失/爆炸的措施还有许多,例如加入BN层、使用ResNet等等
但避免以S型函数作为激活函数是最基本的措施,所以在深度学习中,基本都是使用ReLu函数
好了,以上就是深度学习中的梯度消失与梯度爆炸了~
End
 评论
评论