本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
LVQ学习矢量量化(Learning Vector Quantization)是一种用于解决样本分类问题的神经网络
本文讲解LVQ的模型表达式、聚类机制以及训练方法,并展示一个LVQ解决聚类问题的代码例子
通过本文,可以快速了解LVQ神经网络是什么,以及如何训练一个LVQ神经网络来解决聚类问题
本节讲解LVQ的模型表达式和LVQ神经网络拓扑图,快速了解LVQ模型是什么
LVQ神经网络是什么
LVQ学习矢量量化(Learning Vector Quantization)是一种用于解决样本分类问题的神经网络
LVQ的思想如下:
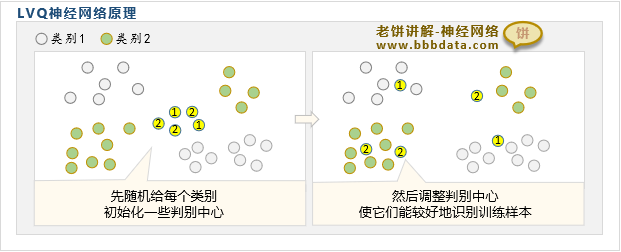
如图所示,LVQ先对每个类别都初始化一些判别中心,每个判别中心的背后都代表一个类别
然后通过训练来调整这些判别中心的位置,使得判别中心能较好地识别训练样本的所属类别
这样,来了新样本,只要判断新样本离哪个判别中心最近,就认为样本属于该判别中心的类别
LVQ的神经网络拓扑图与数学表达式
LVQ模型一般用一个三层神经网络来表示,它的拓扑结构如下:
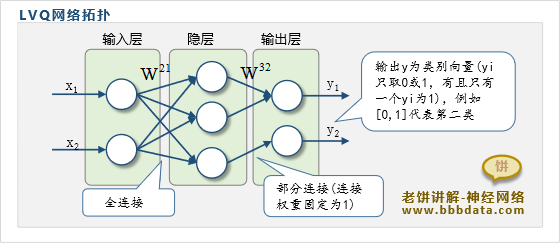
其中,每个隐层节点都代表着一个判别中心,每个输出层节点则代表着一个类别
每个隐节点都与输入层所有节点连接,连接权重就是它所代表的判别中心的位置
每个隐节点只与一个输出节点连接,它与哪个输出节点连接就代表属于哪个类别
LVQ的隐层和输出层的值分别如下:
隐层的值为:
输出层的值为:
其中,
:每一行代表一个判别中心的位置
: 每一列代表着判别中心所属的类别
:欧氏距离函数
:向量竞争函数,即向量中最大值者为1,其它为0
预测时,哪个隐节点为1,就代表样本属于哪个判别中心,再经过输出层的运算来得到样本的类别
✍️ 附:LVQ判别的具体计算例子
以 为例
(1) 计算与各个判别中心的负距离
(2) 计算哪个判别中心胜出
(3)计算输出
本节简单讲述LVQ的两种训练方法:LVQ1和LVQ2
LVQ的训练方法概述
LVQ模型的训练就是调整判别中心的位置(备注:不需要训练)
LVQ模型对的训练方法有两种:LVQ1规则与LVQ2规则,其中LVQ2是LVQ1的改进
LVQ1和LVQ2都是使用逐样本更新的方法,它每次只用一个样本来调整判别中心的位置
LVQ1训练方法
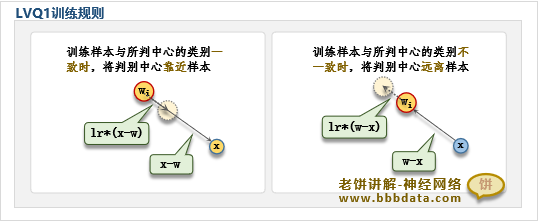
LVQ1规则较为简单,它根据预测的准确性来更新隐节点,如下:
即,如果样本预测正确,就将当前胜出的判别中心往样本靠近,否则远离样本
在数学表述上,则为如下的更新公式:
其中lr为学习率
这里的w指的是竞争胜出的隐神经元与输入所连接的权重,也就是竞争胜出的判别中心的位置
LVQ2训练方法
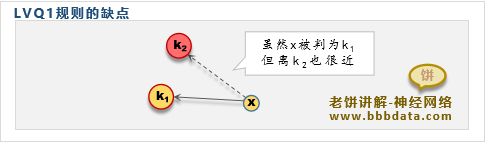
LVQ2解决LVQ1训练后,可能会有些样本属于中心A,又差不多属于B的问题
虽然对训练样本的判别没问题,但“界限”不够清晰,会影响实际预测效果
因此,引入LVQ2规则,使样本点尽量更“清晰”地划分于某一个判别中心
在讲述LVQ2规则前,我们先对相关符号进行说明
✍️ 符号说明
k1 :离样本最近的判别中心(即所竞争成功的隐节点)
k2 :离样本次近的判别中心
d1,d2 :分别代表样本到k1,k2的距离
LVQ2规则详细描述如下:
如果 ,则对判别中心作如下更新:
上式的意义为"d1和d2差别不大",其中 一般取0.25,此时s=0.6
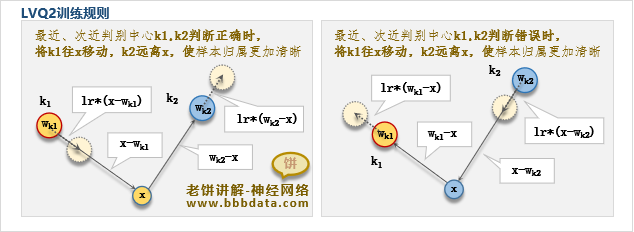
如果判别中心k1、k2对样本类别的判断准确 ,则将k1靠近样本,将k2远离样本
如果判别中心k1、k2对样本类别的判断不准确,则将k2往样本靠近,k1远离样本
用数学表述则为:
相比于LVQ1,LVQ2考虑了次近节点的位置,使界限更为清晰
本节展示如何实现一个LVQ模型用于类别识别
LVQ神经网络代码实现
在matlab中使用newlvq函数来构建一个LVQ神经网络
详细代码示例如下:
%代码说明:matlab工具箱训练一个LVQ神经网络
%来自《老饼讲解神经网络》www.bbbdata.com ,matlab版本:2018a
% ----数据准备--------
clear all ;close all
rand('seed',70)
P = [-3 -2 -2 0 0.5 -0.5 0 +2 +2 +3; ...
0 +1 -1 +2 +1 -1 -2 +1 -1 0]; % 输入数据
Tc = [1 1 1 2 2 2 2 1 1 1]; % 输出类别
T = ind2vec(Tc); % 将输出转为one-hot编码(代表类别的01向量)
% -----网络训练---------
net = newlvq(P,4,[0.5 ,0.5],0.01,'learnlv1'); % 建立一个LVQ神经网络,这里共设4个隐节点,按0.5,0.5分配于两个类别
net = train(net,P,T); % 训练神经网络
Y = sim(net,P); % 预测(one-hot形式)
Yc = vec2ind(Y); % 将one-hot编码形式转回类别编号形式
% 提取出各个类别的判别中心
W21 = net.iw{1,1}; % 判别中心W21
W32 = net.lw{2,1}; % 判别中心的类别W32
% -------打印结果-----------------
disp('判别中心W21:')
W21
disp('判别中心的类别W32:')
W32
disp('样本的真实标签Tc:')
Tc
disp('样本的预测标签Yc:')
Yc
运行结果如下:

从结果可以看到,模型的预测标签与真实标签一致,成功地对样本的类别进行判别
End
 评论
评论