
本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
AdaGrad全称为自适应梯度下降算法(Adaptive Gradient Algorithm),是梯度下降法的一种改进
在一般的优化算法中,学习率都是统一的,而AdaGrad算法则为每个参数自动调整学习率
本文讲解AdaGrad算法的计算公式、AdaGrad算法的优缺点,并展示AdaGrad算法具体的代码实现例子
本节介绍AdaGrad算法的算法流程
AdaGrad算法是什么
AdaGrad全称为自适应梯度下降算法(Adaptive Gradient Algorithm),它是梯度下降算法的一种改进
在梯度下降算法中,学习率都是统一的,而AdaGrad算法则为每个参数自动调整学习率
记待优化的第i个参数为,AdaGrad算法的更新公式如下:
其中,:参数的梯度
:初始值为0,它实际就是的累计平方和
:学习率
:一个极小的常数,它的作用避免分母为0
可以看到,AdaGrad就是在梯度下降算法的基础上
通过将学习率 除以来对每一个参数的学习率进行自动调整
AdaGrad算法-优缺点
AdaGrad-优点
AdaGrad最大的优点是,它可以一定程度上解决梯度消失引起的训练困难问题
在深度学习中,浅层的参数往往会因为梯度消失而难以调整
而AdaGrad加入了自适应学习率,梯度小的参数会获得更大的学习率,从而缓解了梯度消失问题
AdaGrad-缺点
AdaGrad最大的缺点是,学习率会持续缩小,导致在一定步数后学习率会极小,导致无法继续学习
可以看到,AdaGrad中的就是的累计平方和
在一定步数后,大到一定程度时,学习率就会变得极小,从而无法继续学习
本节展示AdaGrad算法的具体代码实现
AdaGrad算法-代码实现
下面使用AdaGrad算法来求函数的最小值
由于AdaGrad算法需要使用目标函数的梯度,所以需要先算出梯度,如下:
,
AdaGrad算法的具体实现代码如下:
"""
AdaGrad算法求y= (x1-2)^2+(x2-3)^2的最小解
"""
import numpy as np
x = np.array([0,0]) # 初始化x
lr = 2 # 设置学习率
s = np.array([0,0]) # 初始化梯度累计量
esp = 0.000001 # 很小的常数
for i in range(100): # 最大迭代100次
g = np.array([2*x[0]-4, 2*x[1]-6]) # 计算x的梯度
s = s + g*g # 更新梯度累计量
x = x - lr/np.sqrt(s+esp)*g # 调整x
print("第",i+1,"轮迭代:x=[",x[0],",",x[1],"],y=",(x[0]-2)**2+(x[1]-3)**2) # 打印当前结果
if((max(abs(g))< 0.0001) ):break # 如果梯度过小,则退出迭代运行结果如下: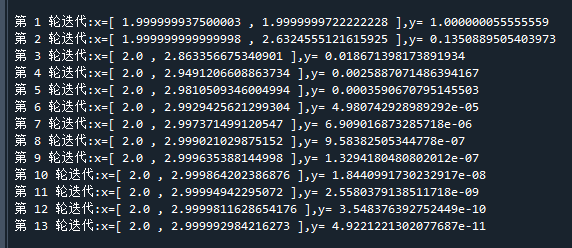
可以看到,经过了13轮迭代,所得到解已经非常接近真实极小解[2,3]
好了,以上就是AdaGrad算法的简单介绍了~
End
 评论 (本站已停止维护,请前往新站点www.bbblearn.com哦)
评论 (本站已停止维护,请前往新站点www.bbblearn.com哦)