本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
KS与AUC类似,是机器学习中常用于二分类模型的模型效果评估指标
本文详细介绍什么是KS,什么是KS曲线,KS的计算公式以及计算KS的计算方法
通过本文,可以快速了解KS、KS曲线是什么,有什么用,以及如何计算KS等等
本节介绍KS的计算公式及如何理解KS的意义
KS的定义与公式
KS和KS曲线有什么用
KS与AUC类似,也是专门用于二分类模型的效果评估指标
一个二分类模型往往是输出如下的评分:
备注:评分越高代表越可能是正样本,当评分大于所设的阈值时,则判为正样本
这类模型一般不用准确率来评估模型效果,而是使用KS曲线和KS指标进行评估
什么是KS
KS全称为Kolmogorov-Smirnov,它的公式定义如下:
其中,
TPR(True PositiveRate)查全率 : 是 1 的样本,被检查出来的概率
FPR(False PositiveRate)虚警率 : 是 0 的样本,被误检成1的概率
✍️老饼点评:如果把TPR看作收益,FPR看作成本,则KS为利润最大值
什么是KS曲线
KS曲线如下图所示:
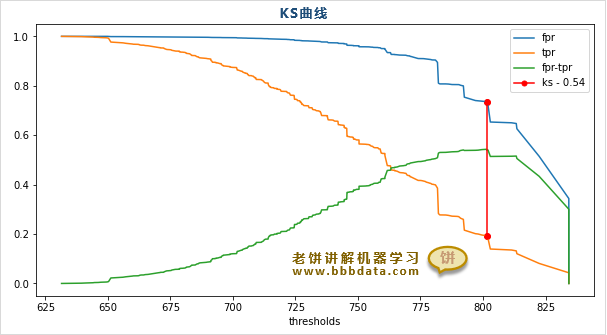
可以看到,以阈值为x轴,TPR、FPR、(TPR-FPR)为y轴所组成的三条变化曲线
然后标出KS的所在位置(即TPR与FPR的最大间隔点),就是KS曲线
本节讲解KS的计算公式以及具体计算方法
KS的计算公式
在实际中,KS更常用的是如下计算公式,会更方便计算
KS计算公式:
解释:即分数小于阈值 的样本中,类0的占比与类1占比差距的最大值
✍️补充
KS的计算公式可由原始定义公式推导得到,推导过程如下
KS计算方法
计算KS常用的两种方法如下:
方式1.通过计算公式计算KS
按score排序,统计0、1标签累计占比,两类标签占比之差最大者,就是KS
0类标签累计占比计算方法为:预测值<阈值b的0标签个数/0标签总个数
1类标签累计占比计算方法为:预测值<阈值b的1标签个数/1标签总个数
方式2.通过定义公式(TPR、FPR)计算KS
先根据score与label计算FPR和TPR,而TPR与FPR之差最大者,就是要求的KS
用python计算KS时,可以调用roc_curve函数获取fpr、tpr,这时用定义公式计算KS更方便
如果是用excel或sql等无法调包直接算得fpr、tpr时,则一般使用计算公式计算KS更简便
本节讲解KS的具体计算方法,从而更形象更具体地了解KS是如何计算出来的
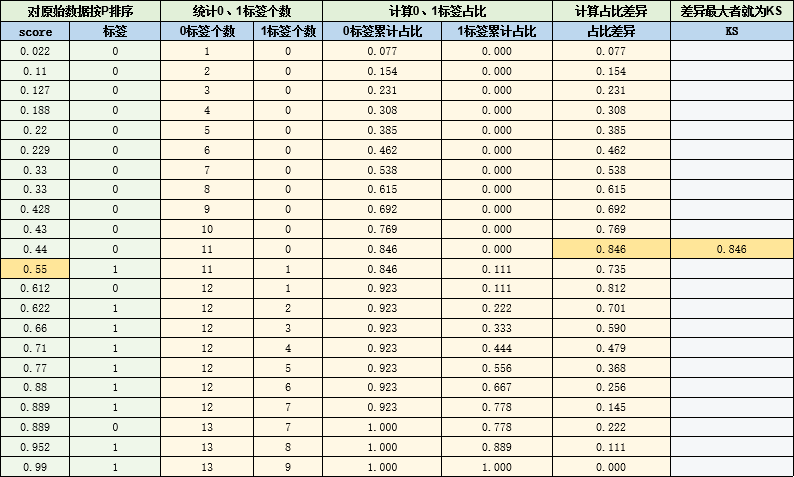
KS实例1-用计算公式计算KS
下面以计算公式的计算方法,计算一个例子
现已获得模型的预测分数和真实标签如下
则KS的计算流程如下:
✍️ 需要注意的是,如上例所示,
KS所对应的阈值应是下一行的0.55,而不是0.846所对应的行的0.44
这是因为上述表格统计占比时用的是"<=",而公式中需要的是"<"
✍️补充 KS模糊计算方法
数据量过大时,为节省计算量,可采用以下分组统计方法:
1.按p排序,并按大小分组,例如分为5组
2.统计每组的(0,1)标签占比、累计占比和累计占比差异
3.占比差异最大者,即为KS值
KS实例2-用定义公式计算KS
使用python代码计算KS时,由于sklearn的roc_curve函数提供了fpr和tpr,
因此,更倾向于用定义公式计算更为简洁,
下面展示一个用python调用sklearn的roc_curve函数计算KS和绘制KS曲线的代码
python计算KS及画KS曲线代码如下
# -*- coding: utf-8 -*-
"""
ks计算DEMO
"""
from sklearn.metrics import roc_curve
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# -----------数据生成----------------------------
score_dict = {'score':[0.71,0.612,0.127,0.330,0.428,0.889,0.188
,0.229,0.889,0.022,0.43,0.952,0.622,0.11
,0.22,0.33,0.44,0.55,0.66,0.77,0.88,0.99]
,'label':[1,0,0,0,0,1,0,0,0,0,0,1,1,0,0,0,0,1,1,1,1,1]} # score与label
df = pd.DataFrame(score_dict) # 将数据转为df
# -------------计算ks-----------------------------
fpr, tpr, thresholds= roc_curve(df.label, df.score) # 计算fpr, tpr
ks_value = max(abs(fpr-tpr)) # 计算KS: abs(fpr-tpr)最大者就是KS
# ----------画KS曲线-------------------------------
thresholds[0] = max(df['score'])+0.01 # 修正thresholds的最大值
plt.figure(figsize=(10, 5)) # 设置图片的大小
plt.plot(thresholds,fpr, label='fpr') # 标示fpr
plt.plot(thresholds,tpr, label='tpr') # 标示tpr
plt.plot(thresholds,abs(fpr-tpr), label='fpr-tpr') # 标示fpr-tpr
plt.xlabel('thresholds') # 标示x坐标轴
# 标记ks
idx = np.argwhere(abs(fpr-tpr) == ks_value)[0, 0]
ks_thresholds = thresholds[idx]
plt.plot((ks_thresholds, ks_thresholds), (fpr[idx], tpr[idx]),
label='ks - {:.2f}'.format(ks_value),
color='r', marker='o', markerfacecolor='r', markersize=5)
plt.scatter((ks_thresholds, ks_thresholds), (fpr[idx], tpr[idx]), color='r')
plt.legend()
plt.show()
print('阈值:',ks_thresholds)
print('KS:',ks_value)运行结果如下:
阈值 : 0.55
KS : 0.8461538
End
 评论
评论