本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
聚类是机器学习中常见的一类问题,它通过样本的近似度将样本聚为一定的类别
本文先介绍聚类问题是什么,聚类的意义,然后通过层次聚类来讲解聚类算法是什么
通过本文,可以初步认识什么是聚类,什么是聚类算法,以及聚类的难点
本节简单介绍什么是聚类问题和聚类问题的意义
什么是聚类
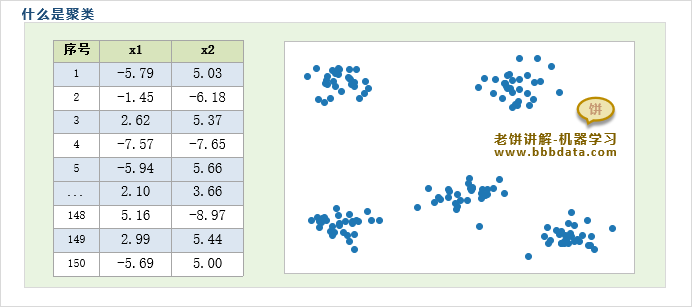
有一组样本数据共150组,包含2个变量,x1和x2,如下
在可视化的情况下,我们很容易就知道,这150个样本可以归为5个类别
但当变量不是2维时,我们就没办法可视化了,也就没办法通过直接观察来划分样本的类别了
聚类问题要解决的是:
如何在不可视化的情况下,对样本划分类别,使相近的样本归为一类
并给出每个样本的类别标签和每个类别的类别中心
聚类的意义
聚类是非常有意义的,下面我们通过两个场景说明聚类问题的意义
聚类问题应用于-降维分析
例如,我们采集了150组发烧病人样本,
如果把发烧病人的症状用聚类方法打上类别标签,最后确定为5个类别,
那么我们分析问题就不需要对150个样本分析,而是降维后的5个类别进行分析
聚类问题应用于-按类别服务
我们对已有客户进行聚类,聚成k类
如果来了新客户,那我们判断他属于哪一个类别,就能针对性提供服务了
例如音乐推荐,先把已有用户聚类,来了新用户,就把和他同一类别的用户喜欢的音乐推荐给他
本节先简单讲述层次聚类法是什么,再泛谈一下聚类算法
层次聚类算法
聚类问题一个较理想的解决方案是“层次聚类算法”,
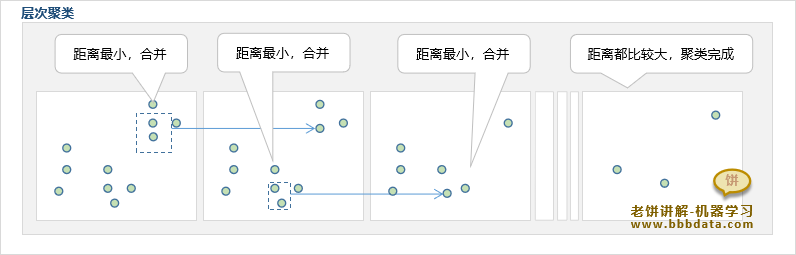
层次聚类算法的聚类流程如下:
层次聚类算法先把所有样本都当成一个类别,每次把最近的两个类别聚合为一个类别(每次减少一个类别)
当类别的距离都比较大,或者类别个数足够小时,就停止聚类
从层次聚类算法的过程可以感受到,层次聚类算法非常有聚类的感觉
从聚类算法谈谈聚类算法
层次聚类算法是一种较为理想、朴素的聚类方法,但它最大缺点是计算量非常大
这是因为每次合并前都要计算所有类别两两间的距离,当样本量较大时,计算量就极极极大
例如10万个样本,那样本两两间的距离就有100亿,这样的计算量几乎无法完成
因此,层次聚类在样本较少时可以使用,但大部分实际情况并不适合使用层次聚类
聚类问题有很多解决方法,但计算量过大往往都是这些聚类方法的通病
而k-means则是一种计算量较小,不会因为数据量暴增而暴增的方法
由于k-means效果不错,且具可行性,因此k-means是日常用得最多的基础入门聚类算法
好了,以上就是聚类问题与层次聚类算法的讲解了~
End
 评论 (本站已停止维护,请前往新站点www.bbblearn.com哦)
评论 (本站已停止维护,请前往新站点www.bbblearn.com哦)