本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
过拟合是机器学习中常遇到的问题,表现往往是训练误差很小,但测试误差很高
本文讲解如何预防过拟合的思路,以及具体的8种常用的预防过拟合的手段与方法
通过本文可以了解可以从哪些方面着手加强模型的泛化能力和具体的预防过拟合措施
本节通过讲解过拟合是什么,过拟合的表现是什么
过拟合与过拟合的表现
过拟合(Overfitting)也称为泛化能力差,它是机器学习中的一种常见现象
过拟合是指在由于模型过度拟合训练数据,导致模型远远偏离X与y的真实关系
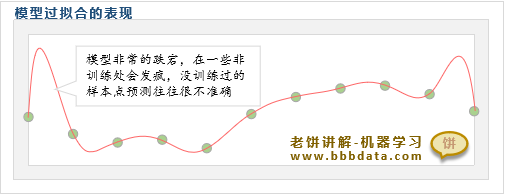
过拟合的直观表现为:
1. 数据表现:模型的训练误差虽然很小,但测试误差很高,泛化能力差
2. 几何表现:模型曲线虽然拟合了训练样本点,但曲线整体扭曲、跌宕、异常
过拟合的详细讲解见《什么是过拟合》
预防过拟合的思路
预防过拟合的思路如下:
1. 增加数据的质量
数据质量是建模成功的前提,数据质量不足会引起各种问题
2. 尽量让样本点与样本点之间平滑过度
特别地,不要让模型在样本点之间发疯突变
3. 尽量充分利用X,y之间的已知关系,使模型更趋向真实关系
一方面让模型尽可能往真实关系靠拢,另一方面尽量剔除不可能的关系
本节提供一些常用的预防过拟合的方法,并展示其原理
预防过拟合的措施
一些常见的预防过拟合的措施如下:
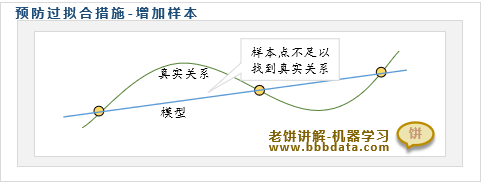
预防过拟合方法一:增加训练数据量
足够的样本才能使模型捕捉到真实关系,同时也可减少噪声样本带来的影响
在训练数据过少的时候,增加训练数据是最直接有效的预防过拟合的措施
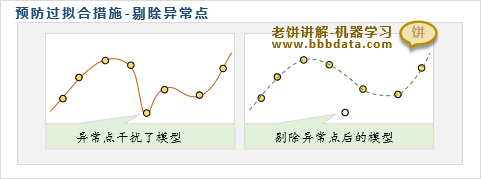
预防过拟合方法二:剔除异常样本
异常点往往是错误样本,由于它过分错误,因此会严重干扰模型的学习
一方面是模型有可能会学习到错误的异常点,使得模型偏离真实关系
另一方面,模型为了兼顾异常点,会间接影响到其它样本的准确学习
因此,剔除异常点能使模型曲线更加平滑,降低采样错误带来的风险
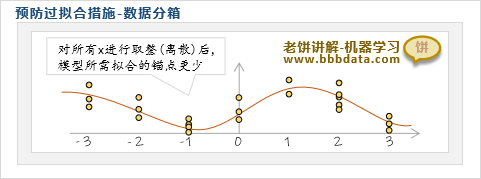
预防过拟合方法三:数据分箱
数据分箱是指在建模前,对输入的每个变量进行离散化,加强抗干扰的能力
它的本质是合理地减少模型所需拟合的锚点,并加强了每个锚点的稳定性
通过对变量进行分箱,可以降低噪声数据带来的影响,使模型曲线更平滑
在模型使用时,既可以使用分箱后的X进行预测,也可以用原始X进行预测
预防过拟合方法四:降低模型复杂度
降低模型的复杂度,也就是限制模型的形态,是一种常用的预防过拟合措施
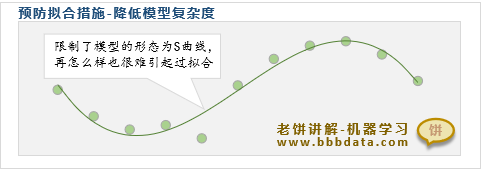
降低模型复杂度,可以削弱模型的拟合能力,使模型更加兼顾全局的拟合
过强的拟合能力会赋予模型学习噪声的能力,增强起伏跌宕,更易过拟合
因此,合理削弱模型拟合能力,限制模型形态,更利于模型找到真实关系
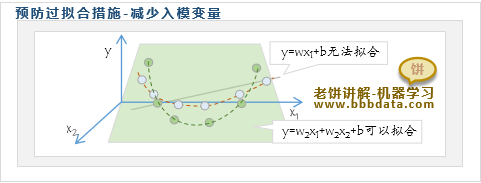
预防过拟合方法五:减少变量个数
减少入模变量也属于降低模型复杂度,高维能拟合低维无法拟合的数据形态
每增加一个变量,模型拟合能力就进一步加强,就赋予了模型过拟合的能力
如图,即使是一个线性回归模型,只要维度足够,它也能拟合任何数据样本
因此,合理地减少变量个数,能降低模型过拟合的可能性,避免模型过拟合
减少变量个数的方法有:手工剔除、运用降维算法降维、逐步回归建模等等
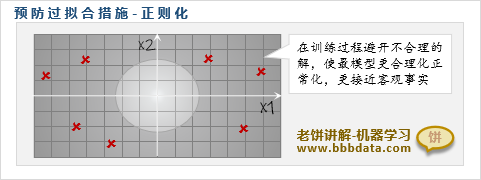
预防过拟合方法六: 使用正则化方法
正则化一般是指在损失函数加入正则项,以此来避免模型训练出不合理的解
一般使用的正则项为L1、L2正则项,可以使模型所求的解的绝对值不要太大
通过正则化,预防模型训练出一些不合理的解,从而使模型更偏向真实关系
正则化除了添加正则项,在深度学习中还有Bn层、Dropout、权重衰减等方法
关于使用正则项预防过拟合的方法可详见《正则化与正则项》
预防过拟合方法七: 早停法(Early Stopping)
早停法是指预留一份验证数据,在训练中使用验证数据检查模型是否过拟合
如图,验证数据的误差越来越大,说明模型走向了过拟合,则提前停止训练
本质上,早停法是通过检验数据来监督曲线的平滑性,保障模型的泛化能力
预防过拟合方法八:集成算法
集成算法是专门为过拟合而设计的一种模型集成方法,一般可取得显著效果
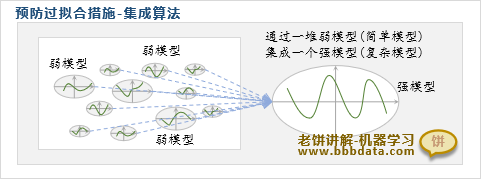
集成算法通过集成多个弱模型来形成一个强模型,既不过拟合又能预测准确
它的原理是在弱模型泛化能力强的基础上,再通过集成多个模型来提高精度
常见的集成方法有:bagging,boosting,stacking等,详细原理各不相同
好了,如何预防过拟合的方法就介绍到这里了
End
 评论
评论