本站原创文章,转载请说明来自《老饼讲解-BP神经网络》www.bbbdata.com
蒙特卡罗算法是一个强大的算法,本文讲解如何使用蒙特卡罗算法来解决手写数字识别问题
通过本文,可以进一步加强对蒙特卡罗算法的理解和实际应用
本节介绍手写数字识别的问题与数据说明
手写数字数据介绍
matlab2018a中自带的digitimages.mat数据就是写手数字的数据,
共包含3000个样本,每个样本是28*28的图片数据,
不妨每个数字都打印5个样本示例,如下

下面我们使用蒙特卡罗法来识别手写数字
本节讲解如何设计一个蒙特卡罗算法来识别手写数字
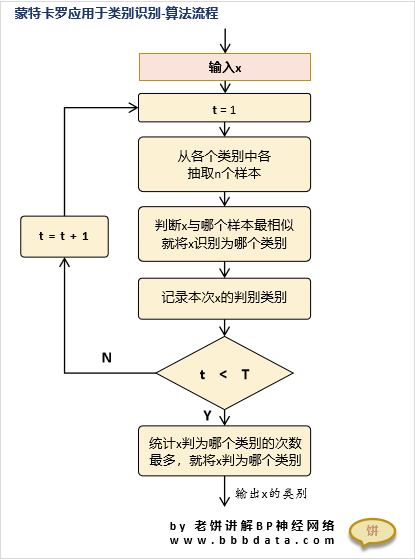
蒙特卡罗法用于手写数字识别的算法设计
蒙特卡罗法用于数字识别的算法设计
数字识别实际也是类别识别
所以算法设计与《螃蟹识别》中的流程是一致的,
具体算法设计如下:
将历史样本存储起来作为一个样本库,
当来了一个新样本时,就在样本库各个类别各抽取n个样本
然后判别新样本中与抽出的样本哪个最相似,就判为哪一个类别
如此重复抽取t次,
最后统计t次中,被判为哪个类别的次数最多,就认为样本属于哪个类别
✍️备注:这里我们使用欧氏距离作为相似度的度量,欧氏距离越小,就认为越相似
蒙特卡罗法用于手写数字识别的算法流程图
算法流程如下:
本节通过代码实现蒙特卡罗法识别手写数字,并展示相关结果
蒙特卡罗法识别手写数字-代码实现
依据上述算法设计,编码蒙特卡罗法用于识别手写数字
共三部分代码
👉1. 预测流程脚本主函数
👉2. 数据处理函数
👉3. 预测函数
具体代码如下:
%------代码说明:展示蒙特卡罗法预测手写数字 -----------------
% 来自《老饼讲解神经网络》www.bbbdata.com ,matlab版本:2018a
global sample_x % 定义样本库的x数据
global sample_y % 定义样本库的y数据
load digitimages.mat % 加载手写数字数据
setdemorandstream(88888);
% 图片数据预处理
[h,w,pic_num] = size(images); % 获取手写数字图片的大小与样本数量
sample_x = zeros(20*20,pic_num); % 初始化图片样本数据
for i = 1:pic_num % 逐张图片处理
cur_x = process_img(images(:,:,i)); % 处理当前图片
sample_x(:,i)=cur_x(:); % 存储当前图片,
end
sample_y = full(ind2vec(Y'+1)); % 将图片对应的数字转为one-hot矩阵
% 数据分割
test_num = 300; % 测试数据个数
test_idx = randperm(pic_num,test_num); % 随机选择test_num个作为测试样本
test_x = sample_x(:,test_idx); % 从样本中抽出测试样本的x
test_y = sample_y(:,test_idx); % 从样本中抽出测试样本的y
sample_x(:,test_idx) = []; % 移除测试样本的x
sample_y(:,test_idx) = []; % 移除测试样本的y
% 通过样本库来预测测试样本对应的数字
py = zeros(size(test_y)); % 初始化预测结果
for i = 1:size(test_x,2) % 逐个样本进行预测
py(:,i)= mc_predict_number(test_x(:,i)); % 预测当前样本
if(mod(i,10)==0) % 每隔10个样本打印一次进度
disp(['进度:',num2str(round(i/test_num*100)),'%']) % 打印当前预测进度
end
end
% 统计与打印预测准确率
y_label = vec2ind(test_y)-1; % 将测试数据的真实结果由one-hot格式转为类别标签形式
py_label = vec2ind(py)-1; % 将预测结果的one-hot格式转为类别标签
acc_rate = sum(py_label==y_label)/length(y_label); % 计算准确率
disp(['预测准确率:',num2str(acc_rate)]) % 打印准确率图片的预处理函数process_img如下:
% 预处理图片的函数
function deal_img = process_img(img)
deal_img = img>50; % 将值>50的作为1,<50的作为0
deal_img = truncImgsPadding(deal_img); % 对图片上下左右空白处进行裁剪
deal_img = imresize(deal_img,[20,20]); % 将图片转换为20*20的Size
end
% 裁剪图片空白边缘部分
function trunc_img = truncImgsPadding(imgs)
% 裁剪左右两边的空白处
sum_imgs = sum(imgs); % 按列求和
csum_imgs = cumsum(sum_imgs); % 计算累计值
[~,right_idx] = max(csum_imgs); % 根据累计值找出右边第一个非0列
left_idx = find(csum_imgs>0); % 根据累计值找出非0列
left_idx = left_idx(1); % 第一个非0列就是左边第一个非0列
trunc_img = imgs(:,left_idx:right_idx); % 进行左右裁剪
% 裁剪上下的空白处
sum_imgs = sum(trunc_img,2); % 按行求行
csum_imgs = cumsum(sum_imgs); % 计行累计值
[~,bot_idx] = max(csum_imgs); % 根据累计值找出底部第一个非0行
top_idx = find(csum_imgs>0); % 根据累计值找出非0行
top_idx = top_idx(1); % 第一个非0行就是顶部第一个非0行
trunc_img = trunc_img(top_idx:bot_idx,:); % 对上下进行裁剪
end蒙特卡罗预测函数mc_predict_number如下:
function y = mc_predict_number(x)
% 用蒙特卡罗法判断样本的类别
global sample_x % 样本库的x数据
global sample_y % 样本库的y数据
setdemorandstream(88888);
t = 100; % 裁决次数
n = 200; % 每个类别抽样数量
[class_num,sample_num] = size(sample_y); % 类别个数与样本个数
class_idx = cell(class_num,1); % 初始化各个类别的样本索引
for i = 1:class_num
class_idx{i} = find(sample_y(i,:)); % 找出属于第i个类别的样本索引
end
% 进行抽样裁决x的类别
rs = zeros(class_num,t); % 初始化裁决结果表
for i = 1:t
select_idx = zeros(n*class_num,1); % 本次抽样的样本索引
for j = 1:class_num % 逐类别抽样
cur_class_idx = class_idx{j}; % 属于第i个类别的样本索引
cur_select_idx = randperm(length(cur_class_idx),n); % 随机抽出n个样本
select_idx((j-1)*n+1:j*n) = cur_class_idx(cur_select_idx); % 记录本次抽出的样本索引
end
select_sample = sample_x(:,select_idx); % 抽取出本次抽样的样本
d = sum((select_sample-x).^2); % 计算各个样本与x的距离
[~,win_idx] = min(d); % 找出最小距离的样本作为本次胜出的样本
win_y = sample_y(:,select_idx(win_idx)); % 根据样本的索引找出y
rs(:,i) = win_y; % 记录本次的获胜的y
end
% 统计多次抽样裁决的结果,用于决定最终x的所属类别
win_stat = sum(rs,2); % 统计各个类别胜出的次数
[~,win_idx] = max(win_stat); % 找出哪个类别胜出次数最多
y = zeros(class_num,1); % 初始化x的类别y
y(win_idx) = 1; % 将胜出次数最多的类别,作为x的类别
end 运行结果
运行结果如下:
从结果可以看到,只是简单的使用均方差作为图片的相似评估函数,预测准确率就已经达到了99.66%
可见,蒙特卡罗算法在手写数字识别上已经达到了较好的效果
比较不足的是,预测速度相对较忙,不如由于它是可并行的,如果改为并行,速度上会加快许多
End
 评论 (本站已停止维护,请前往新站点www.bbblearn.com哦)
评论 (本站已停止维护,请前往新站点www.bbblearn.com哦)