
本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
CART决策树是常用的机器学习算法之一,它包括了CART分类决策树与回归决策树
回归树与分类树不同的地方在于,回归树的输出是数值,分类树输出的是类别
本文展示一个用python(sklearn)实现的简单的CART分类树例子,用于学习sklearn分类树的调用方法
本节展示sklearn实现一个决策树用于解决分类问题的简单例子与代码
决策树分类例子-数据介绍
现已采集150组 鸢尾花数据,包括鸢尾花的四个特征与鸢尾花的类别
数据如下(即sk-learn中的iris数据):
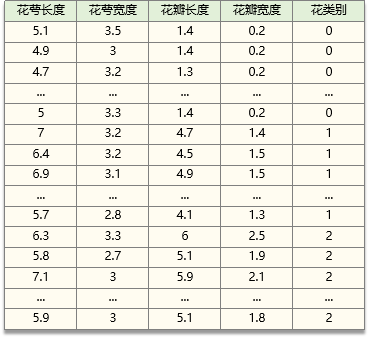
花萼长度 sepal length (cm) 、花萼宽度 sepal width (cm)
花瓣长度 petal length (cm) 、花瓣宽度 petal width (cm)
山鸢尾:0,杂色鸢尾:1,弗吉尼亚鸢尾:2
我们希望通过采集的数据,训练一个决策树模型,
之后应用该模型,可以根据鸢尾花的四个特征去预测它的类别。
决策树分类例子-代码实现
用决策树对以上分类问题进行建模的流程如下:
1. 建立决策树模型
2. 用数据训练决策树模型
3. 用训练好的决策树模型预测
在python中通过sklearn具体实现的代码如下:
from sklearn.datasets import load_iris
from sklearn import tree
#----------------数据准备--------------
iris = load_iris() # 加载数据
#---------------决策树模型训练与预测---------
clf = tree.DecisionTreeClassifier() # 初始化sklearn的决策树模型
clf = clf.fit(iris.data, iris.target) # 用数据训练树模型构建()
r = tree.export_text(clf, feature_names=iris['feature_names']) # 决策树模型的描述
test_x = iris.data[[0,1,50,51,100,101], :] # 测试样本
pred_prob = clf.predict_proba(test_x) # 预测类别概率
pred_target = clf.predict(test_x) # 预测类别
#---------------打印结果--------------
print("\n===模型======\n",r) # 打印决策树模型
print("\n===测试数据:=====\n",test_x) # 打印测试样本
print("\n===预测所属类别概率:=====\n",pred_prob) # 打印测试样本的预测概率
print("\n===预测所属类别:======\n",pred_target) # 打印测试样本的预测类别代码运行结果如下: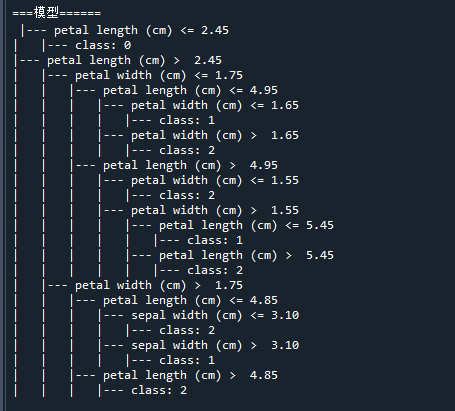
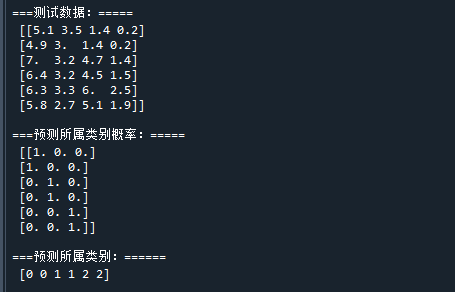
在结果中,展示了训练好的决策树的模型结构,以及测试样本的预测结果
以上就是sklearn实现一个决策树分类的简单例子了~
End
 评论 (本站已停止维护,请前往新站点www.bbblearn.com哦)
评论 (本站已停止维护,请前往新站点www.bbblearn.com哦)