
本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
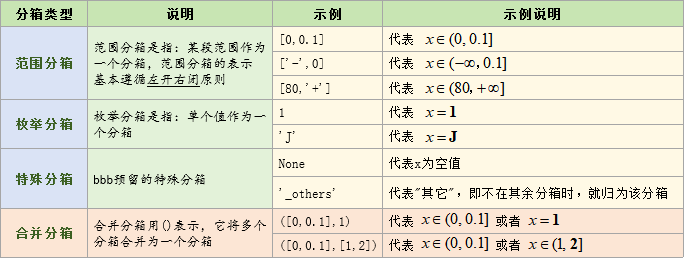
而代表0与>2作为一个分箱,(0,2]作为一个分箱,其它作为一个分箱
更多例子如下:
bin_set= [ [-2,2], [2,5] ] # 代表:(-2,2] , (2,5]
bin_set= [ ['-',2], [2,'+'] ] # 代表:(-inf,2] ,(2,inf]
bin_set= [ [-2,2], [2,5], None, '_other'] # 代表:(-2,2] ,(2,5] ,空值 ,其它
bin_set= [ ([-2,2],None), [2,5] ] # 代表:(-2,2] 与 None , (2,5]
bin_set= [ (1,2,3,4), [4,'+']] # 代表:1、2 、3 、4 , >4bin_sets = {
'age' :[[80,'+'],[60,80],[45,60],['-',45]]
,'city' :[('J','E','I'),'_other',('D','N','S'),('F','P')]
,'marital' :[1,0,2]
,'loan_num':[[3,'+'],(2,3),1,0]
}下面我们先设置分箱,然后统计变量在分箱上的分布,以了解各种分箱配置的实际效果
分箱格式的示例如下:
import bbbrisk as br
# 加载数据
data = br.datasets.load_bloan() # 加载数据
x = data['income'] # rev变量
y = data['is_bad'] # 标签
# 一般的分箱
bin_set =[['-',5000],[5000,9000],[9000,20000],[20000,'+']] # 设置变量的分箱
bin_stat = br.bins.Bins(bin_set).binStat(x,y) # 统计数据在分箱上的分布
print('\n* 连续分箱:\n',bin_stat) # 显示数据的分布
# None的作用
bin_set =[['-',5000],[5000,9000],[9000,20000],[20000,'+'],None] # 设置变量的分箱
bin_stat = br.bins.Bins(bin_set).binStat(x,y) # 统计数据在分箱上的分布
print('\n* 加入了None:\n',bin_stat) # 显示数据的分布
# 如何合并分箱
bin_set =[['-',5000],[5000,9000],[9000,20000],([20000,'+'],None)] # 设置变量的分箱
bin_stat = br.bins.Bins(bin_set).binStat(x,y) # 统计数据在分箱上的分布
print('\n* 将两个分箱合并:\n',bin_stat) # 显示数据的分布
# '_other'的作用
bin_set =[['-',5000],[5000,9000],[9000,20000],'_other'] # 设置变量的分箱
bin_stat = br.bins.Bins(bin_set).binStat(x,y) # 统计数据在分箱上的分布
print('\n* 使用_other作为分箱:\n',bin_stat) # 显示数据的分布运行结果如下:
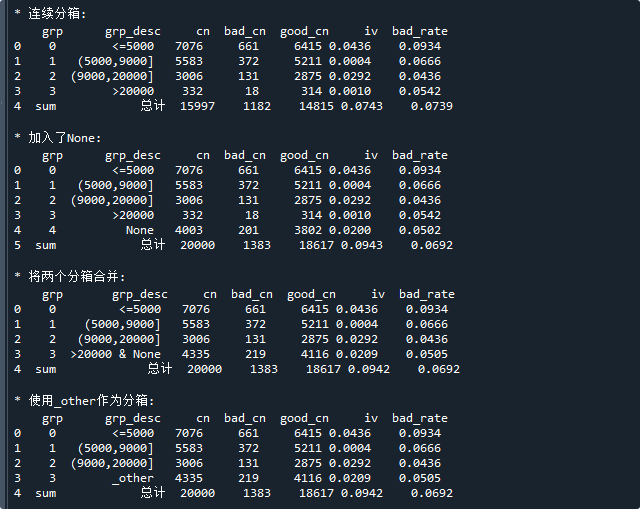
第一种分箱设置,演示了如何将连续变量进行普通的分箱,
但此时各分箱样本总和只有15997个,这是因为变量数据有空值,所以分箱不完整
在第二种设置中,演示了如何将空值进行分箱,此时,总样本个数为20000
在第三种设置中,演示了如何将两个分箱进行合并,这里我们将>20000与None作为一个箱
在第四种设置中,演示了如何将'其它'作为一个分箱,由于None和>20000都不在任意一个分箱,所以它们都属于'其它'分箱
好了,以上就是bbbrisk中分箱的格式说明了~
End
 评论 (本站已停止维护,请前往新站点www.bbblearn.com哦)
评论 (本站已停止维护,请前往新站点www.bbblearn.com哦)