本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
正则化是解决过拟合的一种常用方法,它通过在损失函数中加入正则项来预防模型过拟合
本文讲解正则化是什么,以及正则化常用的L1,L2正则项的公式,并展示正则化的使用例子
通过本文可以快速了解什么是正则化,以及如何使用正则项来进行正则化,使模型泛化能力更好
本节介绍正则化的概念,并通过举例具体说明什么是正则化
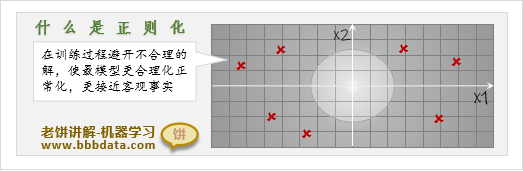
什么是正则化
正则化是机器学习中一种常用于预防过拟合的手段,它可以提高模型的泛化能力
通俗的理解,正则化就是在模型训练过程使模型"更加正常"、"更加合理"的意思
正则化一般通过在模型的损失函数中加入正则项来实现
加入正则项的损失函数一般形式如下:
E代表模型的误差,一般是模型原来的损失函数
而penalty则是惩罚项,用于惩罚不合理的解,则是惩罚系数
通过在损失函数中加入正则项,惩罚不合理的解,使训练出来的模型更加合理
L1、L2正则项与p范
在客观关系中,变量的系数一般不会过大,而且过大的系数易使模型不稳定
所以系数过大时,模型往往是偏离真实关系的,即模型更多时候是过拟合的
正则化最常用的手段是利用为L1、L2正则项来惩罚过大的系数,预防模型过拟合
L1正则项
L1正则项全称为一范正则项,它是所有系数绝对值之和
L1正则项公式如下:
L2正则项
L2正则项全称为二范正则项,它是所有系数的平方和
L2正则项公式如下:
p范正则项
p范正则项以p范数作为正则项,其中p可取为0,1,2,3....
p范正则项公式如下:
L1、L2正则项事实上都是p范正则项取p=1,2时的特殊情况
p范正则项中的p可以取为0或更大的数,但几乎很少用,基本用都只用L1,L2正则项
而最常用的是L2正则项,它可导且导数简单,因此惩罚系数过大时一般都用L2正则项
本节讲解正则项的使用例子,以及使用正则项时的注意事项
正则化例子解说
岭回归与Lasso回归就是线性回归正则化的经典例子,如下:
线性函数最原始的损失函数为:
Lasso回归就是在线性回归的损失函数中加入L1正则项,如下:
岭回归模型则是在线性回归的损失函数中加入L2正则项,如下:
过大的会让损失函数变得非常大,在最小化损失函数时,自然就不会取到得大
正则项的使用注意事项
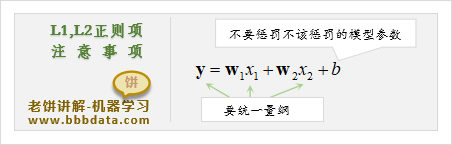
使用L1、L2正则项进行系数惩罚时,需要注意以下两点:
1. 不要惩罚不该惩罚的系数
使用正则项时要考虑参数实际意义,不要惩罚不该惩罚的参数
有些模型参数是可以比较大的,例如阈值很大也不会影响模型的合理性
2. 需要将数据进行归一化
在使用L1、L2惩罚变量的系数时,需要将数据进行归一化
(1)数据归一化后,才更好判断系数的"大与小"
(2)每个变量在统一量纲下,才能公平地惩罚它们的系数
本节通过例子来展示如何在模型中使用正则项进行正则化
正则化使用例子
软件中每个模型往往都有正则项选择,需要正则化时只要设置相关的正则项参数即可
由于每个模型损失函数不同,所以正则化后对模型的具体训练带来的改变也不一样
因此,如果自写代码训练模型,正则化是没有通用方法的,需要具体模型具体讨论
下面以sklearn中的逻辑回归为例,展示如何使用正则化,具体代码如下:
'''
本代码展示在python中逻辑回归模型模型的正则化
本代码来自《老饼讲解-机器学习》www.bbbdata.com
'''
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
#----数据加载----------------------------------
data = load_breast_cancer()
X = data.data[:,0:4] # 用于建模的X,这里只选择前4列进行建模
y = data.target # 用于建模的y
#----输入数据归一化---------------------------
xmin = X.min(axis=0) # 输入变量的最小值
xmax = X.max(axis=0) # 输入变量的最大值
X_norm=(X-xmin)/(xmax-xmin) # 对输入变量进行归一化
#-----不使用正则项训练逻辑回归----------------
clf = LogisticRegression(penalty='none',random_state=0,max_iter=1000) # 初始化逻辑回归模型,不进行正则化
clf.fit(X_norm,y) # 用数据训练逻辑回归模型
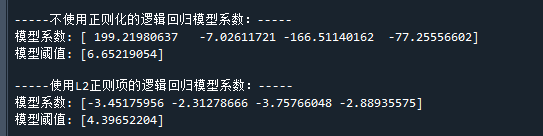
print('\n-----不使用正则化的逻辑回归模型系数:-----') # 打印结果
print( "模型系数:",clf.coef_[0]) # 打印逻辑回归模型系数
print( "模型阈值:",clf.intercept_) # 打印逻辑回归模型阈值
#-----使用L2正则项训练逻辑回归-----------------
clf = LogisticRegression(penalty='l2',C=0.5,random_state=0) # 初始化逻辑回归模型,使用L2正则化
clf.fit(X_norm,y) # 用数据训练逻辑回归模型
print('\n-----使用L2正则项的逻辑回归模型系数:-----') # 打印结果
print( "模型系数:",clf.coef_[0]) # 打印逻辑回归模型系数
print( "模型阈值:",clf.intercept_) # 打印逻辑回归模型阈值运行结果如下:
可以看到,在不使用正则化时,得到的模型系数绝对值非常大,意味着模型非常不稳定
而在使用了L2正则项后,得到的逻辑回归模型系数绝对值普遍都比较小,模型更加正常
在本例中惩罚系数C设为0.5,如果觉得模型系数不够小,可以增大C来加大对系数的惩罚
总的来说,正则化的目的就是避免模型过拟合,增强模型的泛化能力~
End
 评论
评论