本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
Bagging算法是机器学习中一种常用的集成学习方法,它使模型拥有较好的泛化能力
本文讲解Bagging算法的算法流程,算法原理,并展示Bagging集成算法的具体代码实现
通过本文,可以快速了解什么是Bagging算法,以及如何使用Bagging算法来集成模型
本节介绍Bagging算法是什么,以及训练的流程
什么是Bagging集成算法
Bagging是机器学习中模型一种集成方式,由Leo Breiman提出,用于抵抗模型的过拟合
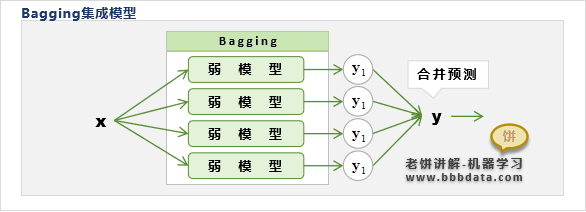
简单来说,Bagging就是独立训练M个弱模型,然后综合M个弱模型进行共同预测,如下:
弱模型是指相对简单、平缓的模型,Bagging集成弱模型的主要目的是为了抵抗过拟合
由于弱模型不易过拟合,但欠拟合,所以Bagging通过集成多个模型来提高模型的预测精度
总的来说,Bagging则是通过集成多个弱模型,使得预测精度提高,同时又保持住弱模型泛化能力强的特点
为什么Bagging能提升模型的泛化能力
下面我们看看Bagging是如何Keep住模型不过拟合,同时又获得高精度模型的
Bagging是如何获得高精度模型的
Bagging中所使用的弱模型并不是毫无要求的、随意的弱模型
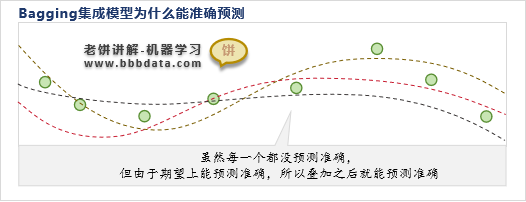
它只是不要求模型本身能精准预测,但它要求弱模型在期望上能够预测准确
以某个样本点为例,每个弱模型对该样本点进行预测时都会得到一个预测值
由于 在期望上等于真实值,所以根据大数定律,多个的均值就迫近真实值
因此,Bagging对某个样本能预测准确的前提是,弱模型在期望上能预测准确,以及弱模型足够多
Bagging是如何控制住模型不过拟合的
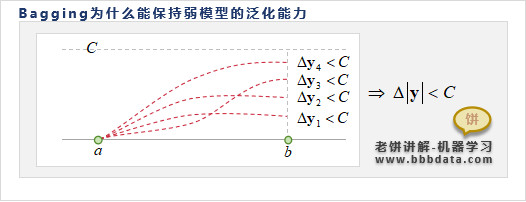
假设Bagging的每个弱模型都是不过拟合,即每个弱模型都是平滑的、非突变的
下面看看多个模型集成之后是如何保持这种平滑的:
不妨取两点来看,每个弱模型从 到 都是非突变的,即
而多个模型平均之后,b点的值相对a点的值的变化为
因此,Bagging将多个弱模型平均之后,也是平滑的、非突变的,即保持了模型的泛化能力
由此可知,Bagging不过拟合的前提是,每个弱模型是平滑的、不过拟合的,这样才能保障集成后不过拟合
本节介绍Bagging集成算法的标准流程如何泛化能力评估方法
Bagging的训练流程
Bagging的标准训练流程
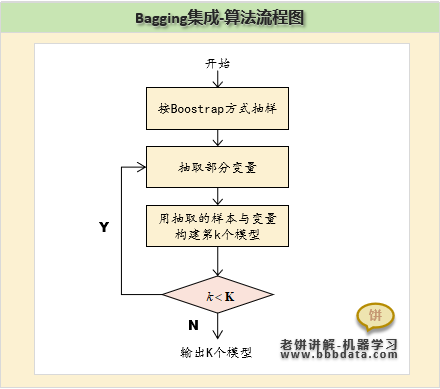
Bagging的模型标准训练流程如下:
即按如下方式训练K个弱模型:
一、 通过boostrap抽取样本
设整体样本有N个,boostrap抽样是指,在整体样本中放回式抽取N次获得N个样本
二、抽出部分变量
一般抽取的变量个数m远小于整体变量个数M,例如
三、使用抽出的数据与变量构建模型
Bagging的预测
Bagging的模型预测方法如下:
👉类别预测:如果每个模型的输出是类别,则进行投票,取投票最多的类别作为Bagging的输出
如果每个模型的输出是概率,则对概率进行求均值,作为Bagging的输出
👉数值预测:如果每个模型的输出是数值,则以所有模型的输出均值,作Bagging的输出
✍️老饼点评
Bagging的目标就是训练出多个不同的弱模型,它主要通过"抽取样本"与"抽取变量"来实现:
👉为什么各个模型不同:由于每个模型所使用的样本、变量不同,因此训练出来的模型各不相同
👉为什么是弱模型:建模样本只是整体样本的子集,变量也只是整体变量的子集,所以训练出来的是弱模型
虽然标准的Bagging是依靠抽样本、抽样本来达到模型的弱化与多样化
但实际中可自由灵活变通,例如通过改变模型参数、加正则项等等方法也可以达到模型的弱化与多样化
Bagging的模型评估-obb_score
袋外得分obb(out-of-bag)-score是一个用来评估Bagging泛化能力的指标
在解释袋外得分之前,不妨先介绍袋外样本和袋外预测的概念
袋外样本:Bagging在训练每个模型时都只用部分样本,而未参与训练的样本就称为该模型的袋外样本
袋外预测:袋外预测是指,每个样本只用该样本不参与训练的模型来对样本进行预测
例如样本A在模型1、3、5中都参与了训练,那么袋外预测就是模型2、4对样本A的预测
袋外得分:袋外得分obb_score是指样本在袋外预测的方式下的准确率
即Bagging可以使用袋外错误率来评估模型的泛化能力,而不需额外预留测试样本来评估泛化能力
本节实现通过代码与例子进一步实现与掌握Bagging袋袋装集成算法
使用sklearn实现Bagging
在python的sklearn中可以使用BaggingClassifier来实现一个Bagging算法
下面我们以集成决策树来展示如何使用Bagging-决策树来对iris实现类别预测
Bagging-决策树具体代码如下:
from sklearn import tree
from sklearn.ensemble import BaggingClassifier
from sklearn.datasets import load_iris
#--------数据准备----------------------------
iris = load_iris() # 加载数据
X = iris.data # 用于模型训练的X
y = iris.target # 用于模型训练的y
#--------模型训练----------------------------
clf = BaggingClassifier(base_estimator=tree.DecisionTreeClassifier() # 使用决策树作为基模型
,max_features = 2 # 每个基模型只用两个变量
,n_estimators = 100 # 构建100个基模型
,oob_score = True # 计算袋外准确率
,random_state = 0)
clf.fit(X, y) # 训练模型
# -------模型预测---------------------------
y_pred = clf.predict(X) # 模型的预测结果
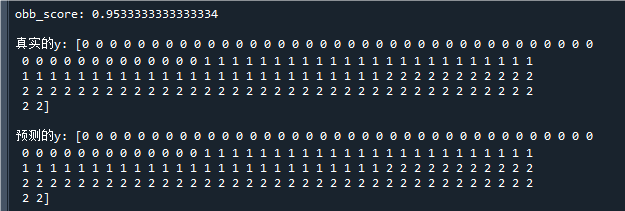
print("\nobb_score:",clf.oob_score_) # 打印模型训练的袋外准确率
print("\n真实的y:",y) # 打印真实标签
print("\n预测的y:",y_pred) # 打印预测标签运行结果如下:
可以看到,模型的obb_score(袋外准确率)为95%,说明模型拥有优秀的泛化能力
自写代码实现Bagging
不调用软件包,自行实现一个Bagging算法的代码如下:
from sklearn import tree
from sklearn.datasets import load_iris
import numpy as np
#--------数据准备----------------------------
iris = load_iris() # 加载数据
X = iris.data # 用于模型训练的X
y = iris.target # 用于模型训练的y
# -------参数设置与模型训练-----------------
k = 100 # 基模型个数
max_feature = 2 # 使用的特征个数
n_sample,n_feature = X.shape # 样本个数与特征个数
n_class = np.unique(y).shape[0] # 类别个数
model_list = [] # 初始化基模型列表
model_feature_list = [] # 初始化每个基模型使用的特征
oob_vote_table = np.zeros((n_sample, n_class)) # 初始化oob投票结果
for i in range(k): # 逐个模型训练
cur_model = tree.DecisionTreeClassifier() # 使用决策树作为基模型
sample_idx = np.random.choice(n_sample, size=n_sample, replace=True) # 有放回式抽取n_sample个样本
feature_idx = np.random.choice(n_feature, size=max_feature, replace=False) # 无放回式抽取max_feature个特征
cur_X = X[np.ix_(sample_idx,feature_idx)] # 当前模型的训练样本X
cur_y = y[sample_idx] # 当前模型的训练样本y
cur_model.fit(cur_X,cur_y) # 训练模型
model_list.append(cur_model) # 保存当前模型
model_feature_list.append(feature_idx) # 保存当前模型使用的变量
# 更新袋外预测投票结果
obb_idx = ~ np.isin(range(n_sample),sample_idx) # 袋外样本的索引
obb_y = cur_model.predict(X[np.ix_(obb_idx,feature_idx)]) # 袋外样本的预测结果
oob_vote_table[obb_idx,obb_y]+=1 # 更新投票
y_obb = np.argmax(oob_vote_table, axis=1) # 根据投票统计袋外预测结果
oob_score = np.mean(y == y_obb) # 计算袋外准确率
# --------模型预测--------------------------
vote_table = np.zeros((X.shape[0], n_class)) # 初始化投票结果
for i in range(len(model_list)): # 逐个模型预测
feature_idx = model_feature_list[i] # 当前模型使用的变量
y_pred = model_list[i].predict(X[:,feature_idx]) # 当前模型对样本的预测
vote_table[range(X.shape[0]),y_pred]+=1 # 更新投票
y_pred = np.argmax(vote_table, axis=1) # 根据投票结果得到最终预测结果
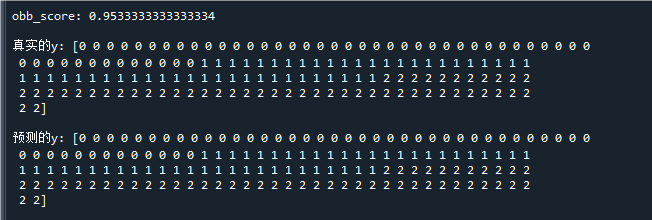
print("\nobb_score:",oob_score) # 打印袋外准确率
print("\n真实的y:",y) # 打印真实标签
print("\n预测的y:",y_pred) # 打印预测标签
运行结果如下:
可以看到模型的预测结果基本是正确的,其中obb_score为95%,说明模型泛化能力也不错
好了,以上就是Bagging集成算法的原理和使用了~
End
 评论
评论