本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
层次聚类法(Agglomerative)分为凝聚法和分裂法,它将每个样本点逐层聚为一类
本文讲解层次聚类算法的算法步骤,聚类过程,所用的距离计算公式,以及代码实现
通过本文,可以快速知道什么了层次聚类算法,如何使用层次聚类算法对样本进行聚类
本节讲解什么是层次聚类算法,以及层次聚类算法的流程
什么是层次聚类算法
层次聚类算法(Hierarchical)是一种最基本的聚类算法,用于对样本进行聚类
层次聚类算法分为凝聚法和分裂法,但层次聚类法一般默认都是指凝聚法,很少用分裂法
层次聚类算法(凝聚法Agglomerative)算法流程如下:
1. 将每个样本初始化为一类,有多少个样本就有多少个类别
2. 计算类别两两之间的距离
3. 将距离最近的两个类别合并为一类
4. 计算新类别与其它类别的距离
重复3,4,直到只剩1个类别(或k个类别)
层次聚类的过程解说
层次聚类算法的聚类过程如下:
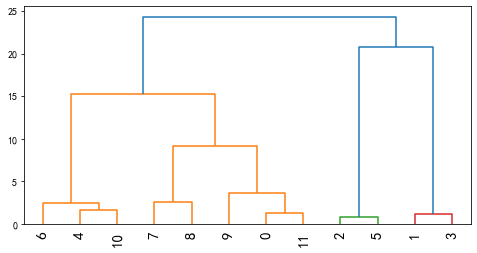
层次聚类算法(凝聚法)是一种自下而上的算法,上图从最底部往上看
从图中可以看到,一共有12个样本,最开始时,它们各自代表着一个类别
根据合并线的高度可以看到,刚开始是2、5合并为一类,然后1、3合并
之后是0、11合并......如此逐层向上,直到最后所有的样本都合并为一类
层次聚类算法-分裂法的流程
分裂法是一种自上而下的算法,很少使用,这里仅作简单介绍
层次聚类算法(分裂法)的算法流程如下:
一、初始化
将所有样本作为一个类别
二、分裂
对每个样本>2的类别进行下述分裂,直到每个类别只有一个样本
每个类别分裂的流程如下:
1. 计算样本两两之间的距离
2. 将距离最远的两个样本作为两个类别中心
3. 将其余样本划分到离它最近的类别中心
4. 以两个类别上的样本均值作为两个类别的位置
本节计算层次聚类算法中常用的的各种距离计算公式
层次聚类法的类别距离
层次聚类法在计算两个类别距离时,一般有如下方法:
1. single:最近邻算法,NPA(Nearest Point Algorithm)
,其中
解释:u的样本与v的样本两两计算距离 ,取最小距离
2. complete:最远邻算法,FPA(Farthest Point Algorithm)
,其中
解释:u的样本与v的样本两两计算距离 ,取最大距离
3. average:等权均值法,UPGMA(Unweighted Pair-Group Methodusing the Average approach)
,其中
解释:u的样本与v的样本两两计算距离 ,取平均距离
4. centroid:等权质心法,UPGMC(Unweighted Paire-Group Method using Centroid approach)
解释:类别u的质心(样本均值)与类别v的质心的距离
5. median: WPGMC,加权质心法(Weighted Pair-Group Method using Centroid approach)
距离的计算与centroid相同
只是将u,v合并时,新类别的位置为u,v质心均值
6. weighted: 加权均值法(Weighted Pair Group Method with Arithmetic mean)
u是刚由s、t两个类别组成的新类别,则u与v的距离计算如下:
解释:两个旧类别s,t与v的距离的平均值
7. ward :ward方差法
ward方差中的距离d指的是:如果u类别与v类别合并时,类内方差SSE的增加量
即 SSE((u,v))-SSE(u)-SSE(v),类内方差SSE是指该类的样本与该类中心的方差之和
如果每次按上述定义计算,计算量会较大,所以一般使用如下迭代公式:
其中,u由s、t两个类别合并而成,代表的样本个数,
其中,ward一般是默认使用方法,其次是single、complete、average等
本节展示如何实现一个层次聚类算法
层次聚类代码实现
在python中虽然用sklearn也能实现层次聚类算法,但它底层调用的其实是scipy
因此,我们这里直接使用scipy来实现层次聚类算法,下面是一个具体的实现例子
层次聚类算法具体代码如下:
import matplotlib.pyplot as plt
from scipy.cluster import hierarchy
import numpy as np
X = np.array([[1 ,2],[3 ,4],[5 ,6],[1 ,8],[2 ,2]]) # 生成数据X
Z = hierarchy.linkage(X,method='ward', metric='euclidean') # 使用层次聚类进行聚类
print('\n聚类过程Z:\n',Z) # 打印聚类结果
plt.figure(figsize=(8, 6)) # 初始化画布
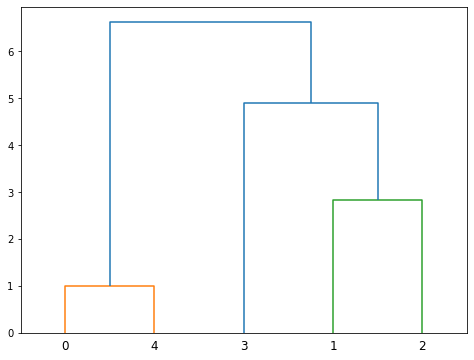
hierarchy.dendrogram(Z) # 绘制聚类过程运行结果如下:
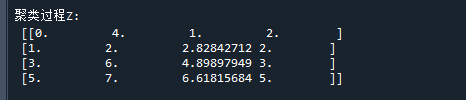
其中,Z记录了合并过程,各列为:类别1,类别2,距离,合并后的样本数
以Z的第一行为例,它的意思是:类别0与类别4的距离为1,合并后样本个数为2
End
 评论 (本站已停止维护,请前往新站点www.bbblearn.com哦)
评论 (本站已停止维护,请前往新站点www.bbblearn.com哦)