本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
本文是评分卡实例中的完整建模代码,实例中的每个细节,都是以此代码为准
通过本文的代码,可以完整的构一个评分卡模型,本代码作为建立评分卡模型时复制与借鉴DEMO
本节对本文的评分卡代码进行简单介绍
评分卡代码-说明
本代码是评分卡实例中的建模代码(不包含变量分析与分箱)
本代码相对较长,主要是为了便于学习,较详尽地展示各个细节
在实际使用时,建议根据实际需要进行分段借鉴
✍️关于代码中使用的数据
这里使用了bbbrisk里的分箱数据(即变量分箱后的数据)进行建模
如果没有安装bbbrisk的,可以通过pip install bbbrisk进行安装
本节展示完整的评分卡建模代码,方便学习、建模时借鉴
评分卡实例-代码
评分卡完整建模代码如下
# -*- coding: utf-8 -*-
"""
评分卡完整建模代码
"""
import pandas as pd
import numpy as np
import math
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn import metrics
import bbbrisk as br
#==============读取数据===================================
raw_data = br.datasets.load_bloan_grp() # 加载bbbrisk的分箱数据
is_bad_col_name = 'is_bad' # is_bad是标签名
#====建模数据预处理:转woe==================
'''获取woe表:特征、特征分组与对应的woe'''
def get_woe_tb(data,is_bad_col_name):
woe_tb = pd.DataFrame() # 初始化woe映射表
sample_num = data.shape[0] # 样本个数
bad_tt = data[is_bad_col_name].sum() # 坏客户个数
godd_tt = sample_num- bad_tt # 好客户个数
for col, row in data.items(): # 逐个变量(即每列)循环
if(col !=is_bad_col_name): # isbad标签列不算变量,不处理
woe_df =data.groupby(col)[is_bad_col_name].agg([('bad_cn','sum'),('cn','count')]) # 按当前变量分组统计坏客户个数与总客户个数
woe_df['grp'] = woe_df.index # 添加组别号
woe_df.loc[woe_df['bad_cn']==0,'bad_cn']=1 # 如果坏客户个数为0,则设为1.这样计算woe才不报错
woe_df.loc[woe_df['bad_cn']==sample_num,'bad_cn'] -=1 # 如果好客户个数为0,则设为1.这样计算woe才不报错
woe_df['woe']=np.log((woe_df['bad_cn']/bad_tt)/((woe_df['cn'] -woe_df['bad_cn'])/godd_tt)) # 按公式计算woe
woe_df['feture'] = col # 记录变量名称
cur_woe_tb = woe_df[['feture','grp','woe']] # 当前的woe表
if(woe_tb.empty): # 如果woe总表为空
woe_tb = cur_woe_tb # 初始化woe总表
else: # 否则
woe_tb = pd.concat([woe_tb,cur_woe_tb],axis=0) # 将当前变量的woe数据添加到woe总表
return woe_tb # 返回woe总表
'''将数据转换为woe '''
def data_to_woe(data,is_bad_col_name):
woe_data = data.copy() # 先将数据复制一份
woe_tb = get_woe_tb(data,is_bad_col_name) # 计算woe映射表
for col, row in woe_data.items(): # 逐个变量(即每列)循环
if(col !=is_bad_col_name): # isbad标签列不算变量,不处理
woe_df = woe_tb[woe_tb['feture']==col] # 将当前变量的woe映射提取出来
woe_dict = {woe_df['grp'][col]:woe_df['woe'][col] for col in woe_df.index} # 将woe映射转换为字典对象{组号:woe值}
woe_data[col] = woe_data[col].map(woe_dict) # 将变量组别转换为woe值
return woe_data,woe_tb # 返回转换后的woe数据,以及woe映射表
# ---将数据转为woe---
data,woe_tb_all = data_to_woe(raw_data,is_bad_col_name) # data是转为woe的数据,woe_tb是每个特征的woe
y = np.array(data[is_bad_col_name]) # y数据(数据中的is_bad列)
X = np.array(data.drop(is_bad_col_name, axis=1)) # x数据(数据中去掉is_bad列)
feature_names = data.columns[data.columns!=is_bad_col_name] # 变量名称
#==============训练模型===========================
'''逐步回归挑选变量'''
def select_feture(clf,X,y,feature_names):
#-----逐步回归挑选变量--------------------
select_fetures_idx = [] # 已挑选的变量
var_pool = np.arange(X.shape[1]) # 待挑选变量池
auc_rec = [] # 用于记录AUC
print("\n===========逐回步归过程===============")
while(len(var_pool)>0): # 如果还有变量,则继续挑选变量
max_auc = 0 # 初始化最佳的AUC
best_var = None # 初始化本轮最佳变量
#---选出剩余变量中能带来最好效果的变量--------
for i in var_pool: # 逐个变量评估"加入该变量的效果"
# -------将新变量和已选变量一起训练模型------
cur_x = X[:,select_fetures_idx+[i]] # 新变量和已选变量作为建模数据
clf.fit(cur_x,y) # 训练模型
pred_prob_y = clf.predict_proba(cur_x)[:,1] # 预测概率
cur_auc = metrics.roc_auc_score(y,pred_prob_y) # 计算AUC
# ------更新最佳变量---------------------------
if(cur_auc>max_auc): # 如果当前变量的AUC更好,
max_auc = cur_auc # 将当前AUC作为最佳AUC
best_var = i # 将当前变量作为最佳变量
#-------检验新变量能否带来显著效果---------------------------
last_auc = auc_rec[-1] if len(auc_rec)>0 else 0.0001 # 未加入本次变量时的AUC
valid = True if ((max_auc-last_auc)/last_auc>0.005) else False # 检查加入本次变量AUC提高是否显著
# 如果有显著效果,则将该变量添加到已选变量
if(valid):
print("本轮最佳AUC:",max_auc,",本轮最佳变量:",feature_names[best_var]) # 打印本轮的最佳AUC和最佳变量
auc_rec.append(max_auc) # 记录本轮AUC
select_fetures_idx.append(best_var) # 将本次选择的变量加入"已选变量池"
var_pool = var_pool[var_pool!=best_var] # 删除待选变量池
# 如果没有显著效果,则停止添加变量
else: # 如果效果不显著,就不再添加变量
print("本轮最佳AUC:",max_auc,",本轮最佳变量:",feature_names[best_var],',效果不明显,不再添加变量')
break
return select_fetures_idx,feature_names[select_fetures_idx] # 返回选择的变量索引以及变量名称
#----数据归一化------
xmin = X.min(axis=0) # X的最小值
xmax = X.max(axis=0) # X的最大值
X_norm =(X-xmin)/(xmax-xmin) # 将X归一化
#将数据分为训练数据与测试数据
X_train,X_test,y_train,y_test = train_test_split(X_norm,y,test_size=0.2,random_state=0) # 将X,y分割为训练数据与测试数据(测试数据20%)
# 初始化模型(备注:penalty一开始训练时先用'none',训练出的系数不满意,再切换回l2)
clf = LogisticRegression(penalty='l2',dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1,
class_weight=None, random_state=0, solver='lbfgs', max_iter=100,
verbose=0, warm_start=False, n_jobs=None, l1_ratio=None)
# ----用逐步回归挑选变量----
select_fetures_idx,select_fetures = select_feture(clf,X_train,y_train,feature_names) # 用逐步回归挑选变量
print("最终选用变量",len(select_fetures),"个:",list(select_fetures)) # 打印挑选的变量名称和变量个数
#----将挑选出的数据进行模型训练-------
clf.fit(X_train[:,select_fetures_idx],y_train)
#=============模型预测与结果评估======================================
pred_y = clf.predict(X_train[:,select_fetures_idx]) # 用模型预测训练样本的好坏标签
pred_prob_y_train = clf.predict_proba(X_train[:,select_fetures_idx])[:,1] # 用模型预测训练样本的坏客户概率
train_auc = metrics.roc_auc_score(y_train,pred_prob_y_train) # 计算训练样本的AUC
pred_prob_y_test = clf.predict_proba(X_test[:,select_fetures_idx])[:,1] # 用模型预测测试样本的坏客户概率
test_auc = metrics.roc_auc_score(y_test,pred_prob_y_test) # 计算测试样本的AUC
pred_prob_y = clf.predict_proba(X_norm[:,select_fetures_idx])[:,1] # 用模型预测所有样本的坏客户概率
print("\n============建模结果=================")
print("最终选用变量",len(select_fetures),"个:",list(select_fetures)) # 打印选择的变量个数
print("AUC:",train_auc) # 打印训练样本的AUC
print("AUC_Test:",test_auc) # 打印测试样本的AUC
#------------提取系数w与阈值b-----------------------
w_norm = clf.coef_[0] # 模型系数(对应归一化数据)
b_norm = clf.intercept_[0] # 模型阈值(对应归一化数据)
w = w_norm/(xmax[select_fetures_idx]-xmin[select_fetures_idx]) # 模型系数(对应原始数据)
b = b_norm - (w_norm/(xmax[select_fetures_idx] - xmin[select_fetures_idx])).dot(xmin[select_fetures_idx]) # 模型阈值(对应原始数据)
#------------打印模型结果信息--------------------------
print("\n=========模型参数==========")
print("模型系数(对应原始数据):",w)
print("模型阈值(对应原始数据):",b)
#===========模型提取与模型预测================================================
# 模型提取
model_feture = feature_names[select_fetures_idx].to_list() # 模型使用的变量名称
woe_tb = woe_tb_all[ woe_tb_all['feture'].isin(model_feture)].reset_index(drop=True) # 模型使用的WOE表格
md_logit ={ 'woe_tb':woe_tb,'model_feture':model_feture,'w':w,'b':b } # 将woe映射表、变量名称、模型权重阈值封装为模型
'''该方法用于模型预测'''
def cal_pred_prob(md,X):
woe_tb = md['woe_tb'] # WOE映射表
w = md['w'] # 模型权重
b = md['b'] # 模型阈值
X_woe = X.copy() # 将X复制一份,用于转换为woe
for feture in md_logit['model_feture']: # 逐变量
woe_df = woe_tb[woe_tb['feture']==feture] # 提取当前变量的woe映射
woe_dict = {woe_df['grp'][col]:woe_df['woe'][col] for col in woe_df.index} # 将woe映射转换为字典对象
X_woe[feture] = X_woe[feture].map(woe_dict) # 将样本的组别转换为woe值
prob_y = 1/(1+np.exp(-(X_woe.dot(w)+ b) )) # 用公式预测
return prob_y # 返回预测结果
# 用提取的模型进行概率预测
model_X = raw_data[md_logit['model_feture']] # 从原始数据中提取出模型预测时的X
prob_y = cal_pred_prob(md_logit,model_X) # 计算模型的预测结果
# 公式计算的概率与sklearn自带概率预测的最大误差
test_self_err = abs(pred_prob_y-prob_y).max()
# ==============将逻辑回归模型转为分数表形式输出模型:===============================
# 依赖于:逻辑回归模型md_logit
#-----从逻辑回归模型中提取相应数据----------
model_feture = md_logit['model_feture'] # 模型所用的变量
b = md_logit['b'] # 模型的阈值
woe_tb = md_logit['woe_tb'].copy() # 模型的woe映射表
#-------分数转换参数设置-----
init_socre = 600 # 初始分数
init_odds = 50 # 初始分数所对应的odd
delta_score = 20 # 增加的分数
delta_rate = 2 # 对应"增加分数",odd所下降的倍数
#----通过factor、offset计算基础分和每个特征每组得分---------
factor = - delta_score/np.log(delta_rate) # 计算factor
offset = init_socre - factor*np.log(init_odds) # 计算offset
base_score = offset + factor*b # 计算基本分
score_tb = woe_tb.copy() # 计算特征得分表
for i in range(len(model_feture)): # 逐变量记录特征系数
score_tb.loc[score_tb['feture'] == model_feture[i],'coef'] = md_logit['w'][i] # 特征系数
score_tb['score'] = factor*( score_tb['coef']*score_tb['woe'] ) # 计算特征得分
#----模型输出:基础分,每个特征每组得分表,模型特征名称---------
md = {'score_tb' : score_tb,
'base_score' : base_score,
'model_feture' : model_feture}
# ==============通过模型计算分数(以评分卡表的形式)=====================================
#---分数计算函数------
def cal_score(md,X):
# -----提取模型数据--------
score_tb = md['score_tb'] # 特征得分表
base_score = md['base_score'] # 基础分
fetures = md['model_feture'] # 模型特征
# -----将分数表转成字典形式----------
score_dict ={feture:{} for feture in fetures} # 初始化特征得分字典
for i in range(score_tb.shape[0]): # 将特征得分表中的数据逐条记填充到字典
feture = score_tb.loc[i,'feture'] # 本次的特征
grp = score_tb.loc[i,'grp'] # 本次的组别
score_dict[feture][grp]= score_tb.loc[i,'score'] # 记录当前特征、组别所对应的分数
# -----将特征组别转换成分数 --------
score = X[fetures].copy() # 将X复制一份,作为分数的初始值
for col in fetures: # 逐个变量转换为分数
score[col]= score[col].map(score_dict[col]) # 将当前变量的组别转换为分数
#-------计算总得分---------------------------
score['base_score'] = base_score # 添加基础分
score['score'] = score.sum(axis=1) # 计算总分
return score # 返回总评分
#---计算样本的分数------
model_X = raw_data[md['model_feture']]
pred_rs = cal_score(md,model_X)
pred_rs['is_bad'] = raw_data['is_bad']
#=========================计算分数阈值表并查看分数分布===============================
# 依赖:pred_rs:存放样本客户的评分score与标签is_bad的
#----阈值表计算函数-----
def cal_score_threshold_tb(score_df,bin_step=10,is_bad_col_name='is_bad',score_col_name='score'):
# -----计算分组起始结束字段--------------
bin_start = math.trunc(score_df[score_col_name].min()/bin_step)*bin_step
bin_end = math.trunc(score_df[score_col_name].max()/bin_step+1)*bin_step
score_thd = pd.DataFrame(columns=['分组名称','本组客户','本组好客户','本组坏客户'])
#-----统计分组内的好坏客户个数-------
for cur_bin in range(bin_start,bin_end,bin_step):
cur_bin_name ='['+str(cur_bin)+'-'+str(cur_bin+bin_step)+')'
cur_score_df = score_df[(score_df[score_col_name]>=cur_bin)&(score_df[score_col_name]<cur_bin+bin_step)][is_bad_col_name]
bad_cn = cur_score_df.sum()
cn = cur_score_df.shape[0]
score_thd.loc[score_thd.shape[0]]=[cur_bin_name,cn,cn-bad_cn,bad_cn]
#------计算阈值表其它字段-------------------
score_thd['总客户'] = score_thd['本组客户'].sum()
score_thd['总好客户'] = score_thd['本组好客户'].sum()
score_thd['总坏客户'] = score_thd['本组坏客户'].sum()
score_thd['阈值'] = score_thd['分组名称'].apply(lambda x: '<'+x.split('-')[1].replace(')',''))
score_thd['损失客户'] = score_thd['本组客户'].cumsum()
score_thd['损失客户%'] = score_thd['损失客户']/score_thd['总客户']
score_thd['损失好客户'] = score_thd['本组好客户'].cumsum()
score_thd['损失好客户%'] = score_thd['损失好客户']/score_thd['总好客户']
score_thd['剔除坏客户'] = score_thd['本组坏客户'].cumsum()
score_thd['剔除坏客户%'] = score_thd['剔除坏客户']/score_thd['总坏客户']
tmp = score_thd['本组客户'].copy()
tmp[tmp==0] = 1
score_thd['本组坏客户占比'] = score_thd['本组坏客户']/tmp
score_thd['损失客户中坏客户占比'] = score_thd['剔除坏客户']/score_thd['损失客户']
return score_thd
# --------计算分数阈值表---------------
score_df = pred_rs[['score','is_bad']]
score_thd = cal_score_threshold_tb(score_df,bin_step=10)
# --------画出分数分布------------------
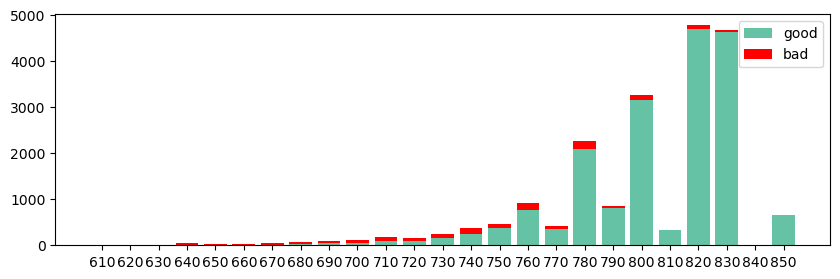
x_axis = score_thd['分组名称'].apply(lambda x: x.split('-')[0].replace('[',''))
plt.bar(x_axis, score_thd['本组好客户'], align="center", color="#66c2a5",label="good")
plt.bar(x_axis, score_thd['本组坏客户'], align="center", bottom=score_thd['本组好客户'], color='r', label="bad")
plt.rcParams["figure.figsize"] = (9, 4) # 设置figure_size尺寸
plt.legend()
plt.show()代码运行结果如下:
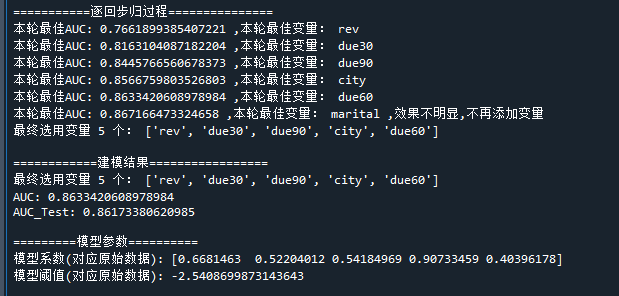
可以看到,用逐步回归选择了5个变量作为最终的入模变量,最终建模AUC为0.86
从分数分布图中可看到,分数分布倾向于二八分布(帕累托分布),在国内小贷中,则是正态分布更常见些
评分卡实例-代码说明
代码主要包括五个模块:
1、分组转woe
将分组数据转换为woe数据
2、建模
(1) 数据归一化
(2) 逐步回归挑选变量
(3) 训练逻辑回归模型
(4) AUC打印
(5) 提取模型参数
3、模型提取与生成评分卡
(1) 提取逻辑回归模型
(2) 生成评分卡
(3) 展示如何利用评分卡对样本评分
4、生成阈值表
计算样本评分,对分数进行分段,最后统计阈值表
5、评分分布图
画出样本评分在各分段的分布
好了,以上就是评分卡的完整建模代码了~
End
 评论
评论