本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
制作评分卡需要先对变量进行分箱,再使用逻辑回归模型进行建模,并将模型转为评分卡表
本文展示一个用bbbrisk实现评分卡的具体例子,包括变量分箱、建模等,并解说代码的运行结果
通过本文,可以了解如何使用bbbrisk来实现一个评分卡,包括分箱、建模、以及相关注意事项
本节介绍本文评分卡案例中使用的数据
bbbrisk简介
bbbrisk是python的一个风控包,目前提供的功能主要是构建评分卡
bbbrisk的优点是,不仅仅是单纯的提供评分卡模型,而是实际构建评分卡时一切可能用到的功能
例如,变量的分析、分箱,模型的训练,评分卡表的构建,最终的报告等等
在使用bbbrisk时,直接pip安装就可以了,如下:
pip install bbbrisk
bbbrisk依赖于numpy、pandas和sklearn包,最好尽可能保障已经安装了这三个包
评分卡案例-数据介绍
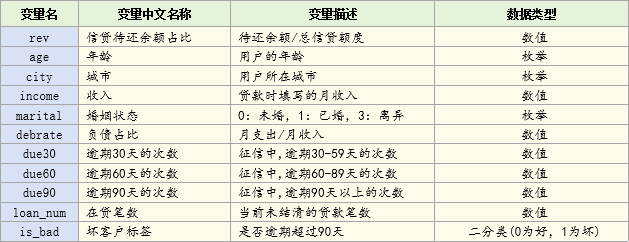
bbbrisk自带的小贷数据共包含10个变量与客户好坏标签
数据包含的10变量和标签如下:
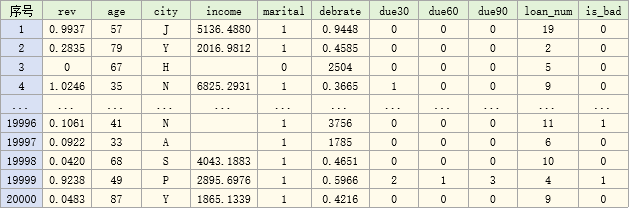
数据共2万条,示例如下:
本节讲解如何对变量进行分箱,以及代码实现
变量分析与分箱(自动)
在构建评分卡之前,需要先对变量进行分析与分箱,并选择出有效的变量作为建模变量
如果只是粗糙地看一下评分卡的效果,变量的分箱可以使用算法进行自动分箱
bbbrisk包提供了bins.autoBin函数来对多个变量进行自动分箱
具体代码如下:
import bbbrisk as br
# 加载数据
data = br.datasets.load_bloan() # 加载数据
x = data.iloc[:,:-1] # 变量数据
y = data['is_bad'] # 标签数据
# 自动分箱
bin_sets = br.bins.batch.autoBins(x, y,enum_var=['city','marital']) # 自动分箱,如果有枚举变量,必须指出哪些是枚举变量
bin_stats = br.bins.batch.bin_stats(x,y,bin_sets) # 统计各个变量的分箱情况
br.display.pd.set(width=300,max_colwidth=30,max_rows=30) # 美化pandas的显示方式
for var in bin_stats: # 逐个变量打印分箱结果
print('\n变量'+var+'的分箱结果:\n',bin_stats[var]) # 打印当前变量的分箱统计结果
# 选择iv足够大的变量
select_bin_set = {} # 初始化选择的变量的分箱
for var,stat in bin_stats.items(): # 逐个变量循环
if (stat['iv'].iloc[-1]>0.1): # 当前变量的iv值是否满足要求
select_bin_set[var] = bin_sets[var] # 如果满足,则添加到选择池
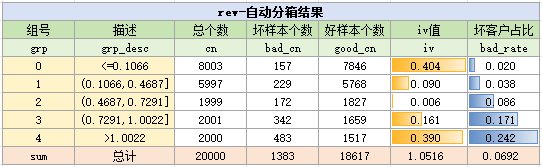
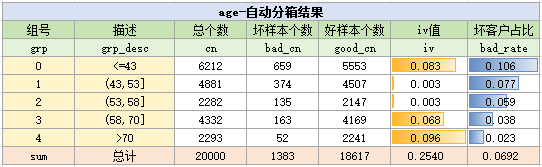
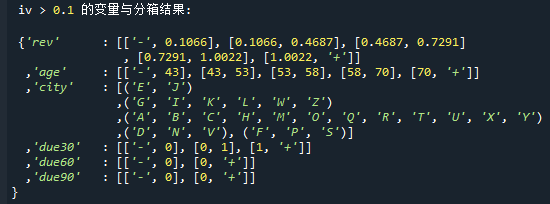
print('\n iv > 0.1 的变量与分箱结果:\n',select_bin_set) # 最终选择的变量的分箱在代码中,先用binning.autoBin函数对变量进行分箱,分箱结果如下:
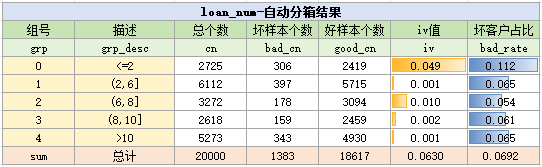
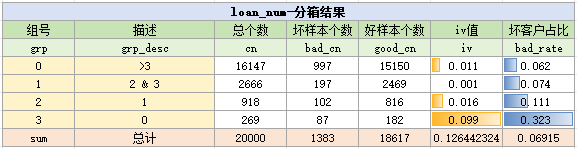
进一步使用bins.bin_stat函数,统计出样本在各个分箱的分布、iv值与badrate
结果如下:
...
自动分箱是为了快捷地、自动地完成分箱,所以一般会简单地借助iv值来判断变量的有效性
由于在iv<0.02时,变量普遍被认为无效,在这里我们不妨把条件加严,筛选出iv>0.1的变量
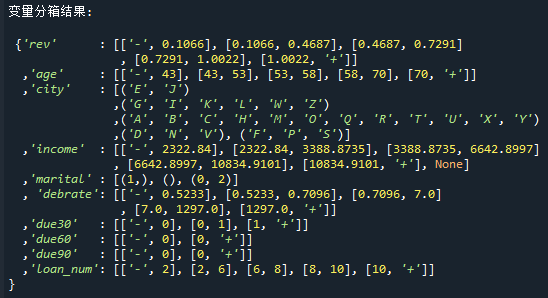
最终选择出的变量以及分箱如下:
变量分析与分箱
在实际项目中,一般都使用手动分箱,来确保评分卡更具解释性、稳定、合理
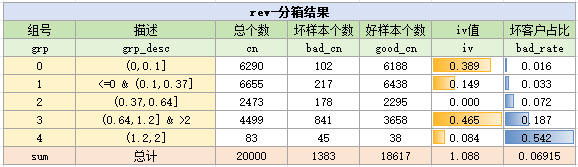
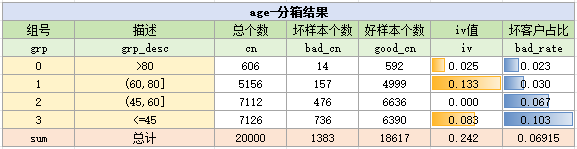
手动分箱一般是指用badrate分析法来进行分箱,并根据badrate来选择出趋势较强的变量
笔者通过手动分箱后的结果如下:
....
在本例中,10个变量最终的badrate都有非常明显的趋势,它们都是有效的
所有变量的分箱代码如下:
import bbbrisk as br
# 加载数据
data = br.datasets.load_bloan() # 加载数据
x = data.iloc[:,:-1] # 变量数据
y = data['is_bad'] # 标签数据
# 变量的分箱
bin_sets = {
'rev' :[[0,0.1],(['-',0],[0.1,0.37]),[0.37,0.64],([0.64,1.2],[2,'+']),[1.2,2],]
,'age' :[[80,'+'],[60,80],[45,60],['-',45]]
,'city' :[('J','E','I'),'_other',('D','N','S'),('F','P')]
,'income' :[[1000,5000],[5000,9000],(['-',1000],[20000,'+'],None),[9000,16000],[16000,20000]]
,'marital':[1,0,2]
,'debrate':[([0,0.1],[850,'+']),([0.1,0.5],[5,850]),([0.5,0.8],0),[0.8,5]]
,'due30' :[0,1,2,(3,4),[4,'+']]
,'due60' :[0,1,2,[2,'+']]
,'due90' :[0,1,[1,'+']]
,'loan_num':[[3,'+'],(2,3),1,0]
}
bin_stats = br.bins.batch.bin_stats(x,y,bin_sets) # 统计各个变量的分箱情况
br.display.pd.set(width=300,max_colwidth=30,max_rows=30) # 美化pandas的显示方式
for var in bin_stats: # 逐个变量打印分箱结果
print('\n变量'+var+'的分箱结果:\n',bin_stats[var]) # 打印当前变量的分箱统计结果
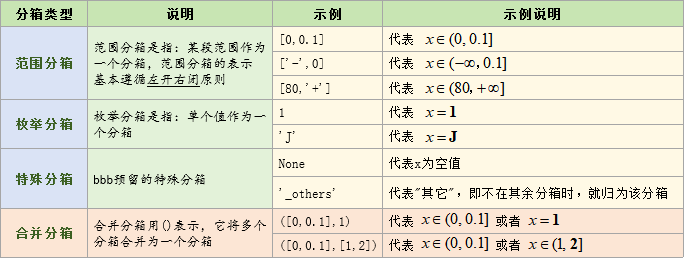
✍️关于bbb的分箱格式
在bbbrisk中,约定每个变量的分箱都以list来表示,list中第i个元素代表第i个分箱
其中,单个箱体的表示方法如下:
简单来说,主要就三种情况:
1. 如果是范围分箱,就用[a,b]格式
它遵循左开右闭,即它实际代表的范围是(a,b],如果要左闭,就把a取小一点
2. 如果是枚举值就直接填上枚举值a
3. 如果要合并,就用小括号()括起来,例如([a,b],[c,d],e)
举例:代表0作为一个分箱,(0,2]作为一个分箱,>2作为一个分箱
代表0与>2作为一个分箱,(0,2]作为一个分箱,其它作为一个分箱
本节讲解如何用代码实现评分卡,以及计算阈值表、分数分布图等
评分卡-实现代码
在完成变量分箱后,就可以直接使用bbb的评分卡包来构建评分卡,以及打印相关报告
具体代码如下:
import bbbrisk as br
#加载数据
data = br.datasets.load_bloan() # 加载数据
x = data.iloc[:,:-1] # 变量数据
y = data['is_bad'] # 标签数据
# 变量的分箱
bin_sets = {
'rev' :[[0,0.1],(['-',0],[0.1,0.37]),[0.37,0.64],([0.64,1.2],[2,'+']),[1.2,2],]
,'age' :[[80,'+'],[60,80],[45,60],['-',45]]
,'city' :[('J','E','I'),'_other',('D','N','S'),('F','P')]
,'income' :[[1000,5000],[5000,9000],(['-',1000],[20000,'+'],None),[9000,16000],[16000,20000]]
,'marital':[1,0,2]
,'debrate':[([0,0.1],[850,'+']),([0.1,0.5],[5,850]),([0.5,0.8],0),[0.8,5]]
,'due30' :[0,1,2,(3,4),[4,'+']]
,'due60' :[0,1,2,[2,'+']]
,'due90' :[0,1,[1,'+']]
,'loan_num':[[3,'+'],(2,3),1,0]
}
# 构建评分卡
model,card = br.model.scoreCard(x,y,bin_sets,train_param={'random_state':0}) # 构建评分卡,为了使结果能重现,笔者设置了固定的随机种子
score = card.predict(x[card.var]) # 用评分卡进行评分
card.featureScore # 评分卡-特征得分表
card.baseScore # 评分卡-基础分
# 打印结果
print('\n-----【 模型性能评估 】----')
print('* 模型训练AUC:',model.train_auc) # 打印模型训练数据集的AUC
print('* 模型测试AUC:',model.test_auc) # 打印模型测试数据集的AUC
print('* 模型训练KS:',model.train_ks) # 打印模型训练数据集的KS
print('* 模型测试KS:',model.test_ks) # 打印模型测试数据集的KS
print('\n--------【 模型 】---------')
print('* 模型使用的变量:',model.var) # 模型最终使用的变量
print('* 模型权重:',model.w) # 模型的变量权重
print('* 模型阈值:',model.b) # 模型的阈值
# 计算阈值表与分数分布图
thd_tb = br.report.get_threshold_tb(score,y,bin_step=10) # 阈值表
br.report.draw_score_disb(score,y,bin_step=10,figsize=(14, 4)) # 分数分布评分卡建模结果
代码运行结果如下:
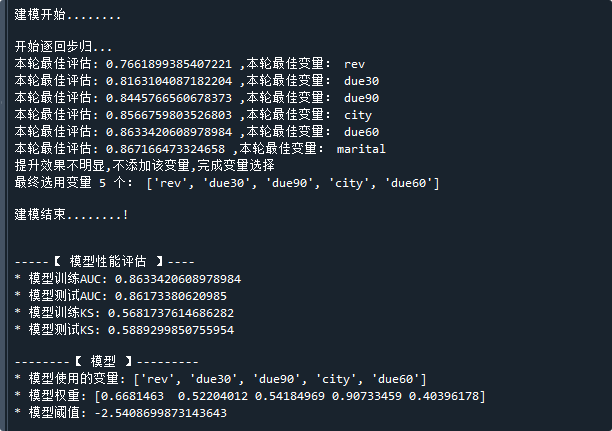
在评分卡建模时,会先用逐步回归筛选变量,减少最终模型使用的变量个数
如图所示,当添加marital变量时,AUC提升不明显,因此不再添加变量,最终只选择5个变量
建模完成后,可以看到模型的训练、测试数据的AUC和KS,以及模型的参数
根据模型的参数,可知最终的逻辑回归模型表达式为:
备注:这里各个变量的值指的是变量的woe,即上式中的rev变量指的是rev变量对应的woe值
评分卡结果
card.featureScore和card.baseScore里分别存放了特征得分与基础分
两者合并后就是最终的评分卡表,如下:
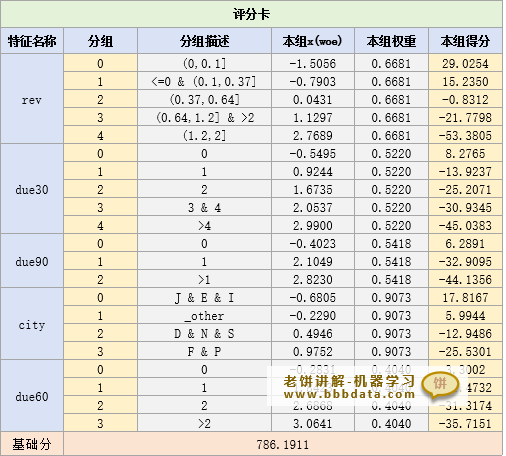
使用上述卡表进行评分,只需计算出每个特征的得分,再加上基础分,就是总评分
如果使用公式进行评分,需先通过card.factor和card.offset得到factor=-28.85,offset=712.87
从而得到评分公式如下:
这里各个变量的值指的是变量的woe,即上式中的rev变量指的是rev变量对应的woe值
阈值表与分数分布图
代码中的report.get_threshold_tb用于计算阈值表,report.draw_score_disb则用于绘制分数分布图
阈值表计算结果如下:
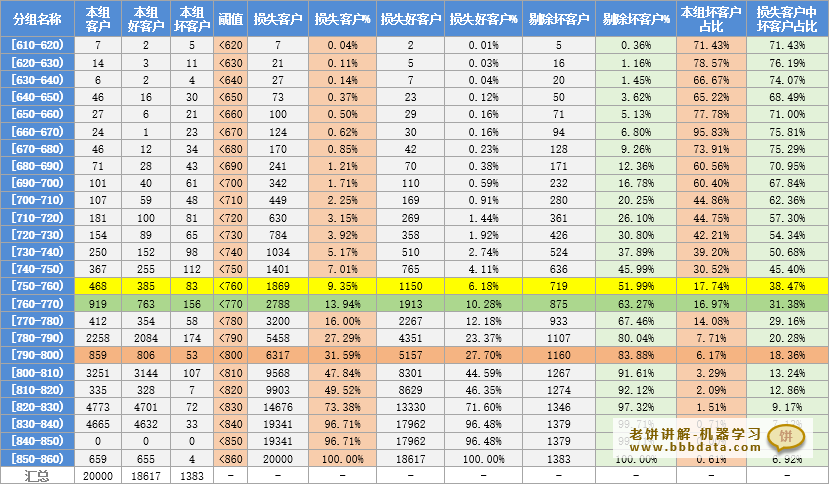
根据阈值表,就可以选择一个合适的阈值,用于判断样本是否能通过,具体方法见《阈值表与评分阈值》
所有样本的分数分布图如下:
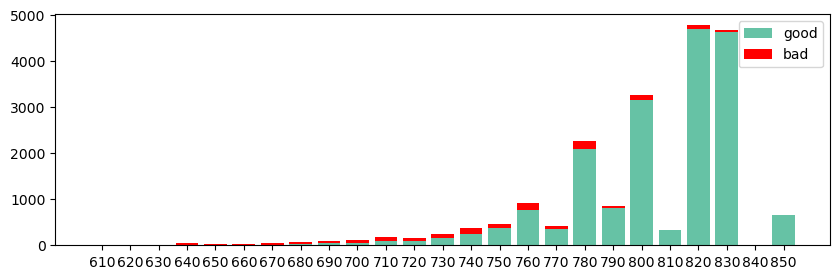
这里的横轴代表的是分数起始值,例如610代表[610,620)之间的样本个数,其中绿色是好样本、红色是坏样本
好了,以上就是如何使用bbbrisk来实现一个评分卡的步骤与代码了~
End
 评论
评论