本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
接上文《评分卡实例-数据准备》
前文提要与本文概述
经过上一节的特征工程,我们得到了处理好的评分卡入模变量数据,即如下的评分卡WOE变量表
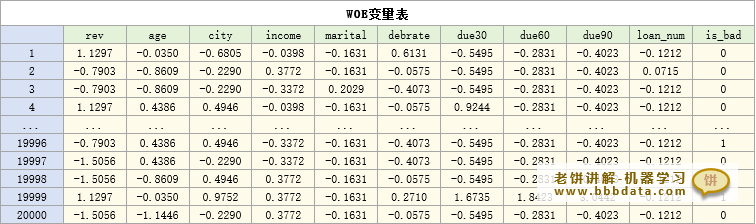
在本文,我们讲解,如何使用这张WOE变量表的数据建立逻辑回归模型
本节讲解评分卡建模前需要做什么数据处理
评分卡建模-数据预处理
评分卡使用逻辑回归模型进行建模,即使用上述的变量表(woe值)来预测"是坏样本"的概率
为了获得更好的建模效果,在建模前需要将数据进行以下处理:
1. 数据归一化
数据归一化是指将数据归一化到[0,1]之间
归一化可以让模型求解效果更好,同时在正则惩罚时能公平地惩罚各个变量
归一化公式如下:
以特征rev为例,它的最小取值、最大取值为-1.5056和2.7689,
因此,对rev变量进行归一化的计算公式如下:
2. 预留测试数据
预留测试数据,用于测试模型的预测效果
一般用80%的数据用于训练模型,预留20%的数据用于模型测试
评分卡建模-变量预筛选
逻辑回归过拟合的原因主要来源于变量个数过多
因此,在保障模型效果的同时,选择尽量少的变量进行建模,可以令模型更不易于过拟合
在评分卡中,一般使用逐步回归的来预筛选变量,减少入模变量个数
什么是逐步回归
逐步回归是挑选模型关键变量的一个常用的方法
简单来说,就是以逐个添加变量的方式进行建模,直到添加变量不能提升模型为止
逐步回归流程如下:
1. 历遍所有变量,将单个变量与y进行建模,把建模结果最好的变量作为第一轮选择变
2. 在第一轮选择变量的基础上,添加第二个变量,
历遍剩余变量,添加哪个变量能令模型结果最好,就将其作为第二轮选择变量
3. 在第二轮的基础上,添加第三个变量......
......
直到变量不再对拟合结果带来明显贡献时,就不再添加变量
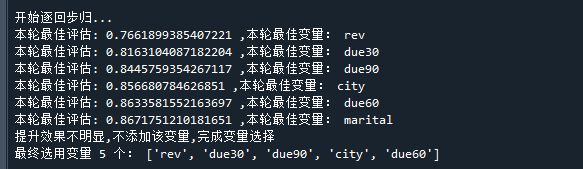
逐步回归筛选变量的过程如下:
可以看到,在加入第6个变量,marital时,AUC增长并不明显,则停止继续添加变量
只使用前5轮挑出的变量:rev,due30,due90,city,due60
本节讲解评分卡建模时模型的正式训练
评分卡-模型训练
逻辑回归模型的训练
逻辑回归模型的训练较为简单,只需将选出的变量,放到逻辑回归模型中建模即可
在python中只需使用sklearn的LogisticRegression就可以训练一个逻辑回归模型
逻辑回归模型可调参数较少,在这一步直接调用模型进行训练即可
代码示例如下:
clf =LogisticRegression(penalty='none')
clf.fit(X_train[:,select_fetures_idx],y_train)
在sklearn中,默认是加入L2正则项的,它可以避免系数过大,但同时会轻微影响模型的精度
因此训练时可先将penalty选项设为'none'(即不进行正则),如果训练的系数不合理,再改用'l2'训练
提取模型的权重阈值
模型训练完成,在sklearn中可以使用clf.coef_、clf.intercept_提取出模型的权重和阈值
本例中提取的权重和阈值如下:
但由于训练前对数据作了归一化,所以直接提取的权重、阈值是面向归一化后的woe数据的
不妨对它进行反归一化,从而得到面向原始woe数据的权重、阈值:
备注:将逻辑回归的权重阈值进行反归一化的方法可参考文章《》
最终得到模型的表达式为:
评分卡建模后的模型评估
评分卡模型的AUC评估
逻辑回归的模型的效果一般使用AUC指标(或KS指标)进行评估
分别计算训练样本和测试样本的AUC,然后根据AUC进行评估模型是否可投产
AUC和投产的关系一般如下
👉AUC>0.63:模型对y有区分度(不可投产)
👉AUC>0.68:模型在生产上开始效益(不可投产)
👉AUC>0.73:模型才算优秀(可投产)
评分卡模型的系数审查
除了评估AUC,还需要检验模型的系数是否符合业务逻辑
1.检查系数符号的合理性
由于经过WOE转换,所有特征与badRate都是正相关,因此,系数应都为正数
如果其中某些变量的系数为负数,需要检验模型哪里出了问题
2. 检查系数在业务的合理性
除了系数的符号,还应留意模型的系数与业务理解有没有太大的出入,
例如,某个变量的系数远远大于其它变量的系数,那也是是不正常的
如果模型AUC过低,或系数异常,则需要返回排查问题,思考原因,这不在本文范畴,有时间再开文详述
评分卡的建模到这里就完成了~ 下张文章我们再讲解如何将模型制作成评分卡
End
 评论
评论