机器学习入门
1.学前解惑
-
1. 1 入门准备
-
1. 2 B站视频
2.第一课:初探模型
-
2. 1 初探模型
3.第二课:逻辑回归与梯度下降
-
3. 1 逻辑回归与梯度下降
4.第三课:决策树
5.第四课:逻辑回归与决策树补充
-
5. 1 熵与逻辑回归、决策树
-
信息与熵
-
基于熵补充学习逻辑回归
-
基于熵补充学习决策树
-
6.第五课:常见的其它算法
-
6. 1 聚类与分类
-
k-means聚类
-
朴素贝叶斯分类
-
PCA主成份分析
-
7.第六课:综合应用
【代码】k-means代码Demo
作者 : 老饼
发表日期 : 2022-06-26 23:31:57
更新日期 : 2023-12-19 19:28:17
本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
本文展示一个简单的python实现的k-means聚类代码Demo.并展示最后的聚类结果
01. k-means代码简介
本节介绍本文代码所实现的内容
k-means代码简介
代码先以5个中心点随机生成150个样本点,
然后使用k-means聚类找出5个类别的中心点
聚类过程
使用k-means算法,先初始化5个聚类中心点,
然后根据k-means的迭代规则,不断调5个聚类中心点的位置
经过20轮迭代后,输出聚类中心点的位置
最后,根据样本所属的聚类中心点,给样本标上颜色
聚类结果如下:
可以看到,每簇样本点都被标上了不同的颜色,说明k-means聚类是成功的

02. k-means实现代码
本节展示K-MEAN的实现代码
k-means实现代码
k-means的实现代码如下
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=150, random_state=10,centers=5) #生成数据
n_sample = X.shape[0]
#设置k值
k = 5
# plt.scatter(X[:, 0], X[:, 1])
# plt.axis('off')
#随机选择k个样本作为中心
init_idx = np.random.randint(0,n_sample,k)
c = X[init_idx,:]
#聚类过程
c_idx = np.zeros(n_sample)#样本的类别
for t in range(20):
#更新样本所属类别
for i in range(n_sample):
c_idx[i] = np.argmin(((c - X[i])**2 ).sum(axis=1))
# 更新类别中心
for i in range(k):
c[i] = X[c_idx==i].mean(axis=0)
#展示结果,以颜色标示类别
plt.scatter(X[:, 0], X[:, 1], c=c_idx)
plt.axis('off')
运行结果
运行代码后可得到Kmeans的聚类结果如下:
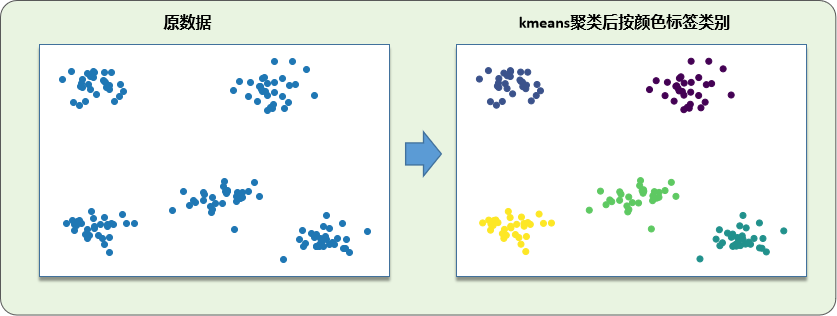
以上就是k-means代码的Demo了~
End