机器学习入门
1.学前解惑
-
1. 1 入门准备
-
1. 2 B站视频
2.第一课:初探模型
-
2. 1 初探模型
3.第二课:逻辑回归与梯度下降
-
3. 1 逻辑回归与梯度下降
4.第三课:决策树
5.第四课:逻辑回归与决策树补充
-
5. 1 熵与逻辑回归、决策树
-
信息与熵
-
基于熵补充学习逻辑回归
-
基于熵补充学习决策树
-
6.第五课:常见的其它算法
-
6. 1 聚类与分类
-
k-means聚类
-
朴素贝叶斯分类
-
PCA主成份分析
-
7.第六课:综合应用
【原理】交叉熵损失函数公式推导
作者 : 老饼
发表日期 : 2023-12-27 19:43:03
更新日期 : 2024-04-06 03:51:21
本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
交叉熵损失函数是机器学习分类模型中常用的一种交叉熵损失函数
本文讲解交叉熵损失函数的公式及推导,以及交叉熵损失函数在模型为二分类时的形式
通过本文可以更加具体、详细地了解交叉熵损失函数
01. 分类模型的交叉熵与交叉熵损失函数
本节讲解分类模型中的交叉熵损失函数的定义及计算公式
什么是分类模型的交叉熵损失函数
分类模型的交叉熵损失函数是基于信息量、交叉熵等概念上建立起来的一种损失函数
分类模型中的交叉熵指:
👉基于模型的判断结果,在知道样本真实类别时,所获得的信息量的期望
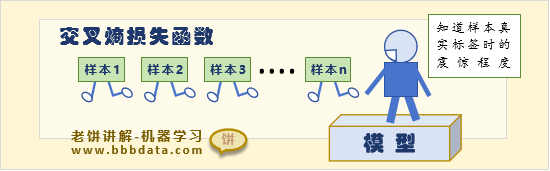
信息量往往代表着惊讶程度,如果模型预测准确的话,那么知道真实标签时,我们当然不会惊讶,
如果惊讶程度越大,说明真实标签大大出乎模型的意料之外,因此,交叉熵代表了模型的准确程度
我们希望交叉熵越小越好,因此,一般把交叉熵作为模型的损失函数,称为交叉熵损失函数
交叉熵损失函数计算公式-定义形式
不妨记第i个样本的真实类别标签为,模型判断第i样本属于类别的概率为
按交叉熵损失函数的定义,可易得交叉熵损失函数计算公式的定义形式如下
交叉熵损失函数计算公式-定义形式:
其中, :样本个数
:模型判断第i个样本属于类别k的概率,k是样本的真实标签
✍️交叉熵损失函数计算公式解读
上述公式是较好理解的,在知道第i个样本真实标签时,获得的信息量为
则所有样本的信息量均值就是信息量期望的估算,也就是交叉熵的估算
交叉熵损失函数计算公式
交叉熵损失函数在计算时为了计算更加方便
往往是先计算出每个类别的信息量期望,再对所有类别进行求和
因此,交叉熵损失函数在实际计算时往往使用的是如下形式:
交叉熵损失函数计算公式-计算形式:
其中,K :类别个数
:第i个样本的真实类别标签
:模型判断第i样本属于第k类的概率
02. 分类模型的交叉熵与交叉熵损失函数
本节讲解交叉熵损失函数在二分类时的形式
逻辑回归模型的损失函数使用的就是该形式
二分类模型的交叉熵损失函数-推导过程
特别地,在二分类模型中,
一般将类别标签记为0/1两类,然后模型输出样本属于1类的概率
则有:👉1. 模型评估0类的样本属于0类的概率为:
👉2. 模型评估1类的样本属于1类的概率为:
则基于模型的判断结果,在知道样本的真实类别标签时,
所获得的信息量的期望(交叉熵)为:
二分类模型的交叉熵损失函数-总结
总的来说,二分类模型的交叉熵损失函数如下:
其中,:样本个数
:第i个本样的真实类别标签
:模型判断第个i样本属于第1类的概率
二分类交叉熵损失函数的意义解读如下:

总的来说,交叉熵损失函数就是希望在模型的预测下,在知道样本真实标签时所受的惊讶越小越好
好了,交叉熵损失函数的公及及推导就讲到这里了~
End